
Fine-tune a Quantized Large Language Model on a Single GPU (Falcon-7B)
Example Python code that to train and fine-tune a quantized large language model on your custom data on a single GPU.
 Dr. Phil Winder
/
9 min
Dr. Phil Winder
/
9 minExample Python code that to train and fine-tune a quantized large language model on your custom data on a single GPU.
Dr. Phil Winder
/
9 min
Where there are large numbers of features it becomes hard to visualise data and can cause problems with computational complexity. This python tutorial introduces dimensionality reduction and principal component analysis.
What to do when you need to perform a distance measure for a nearest neighbour like algorithm, but you have a large dataset?
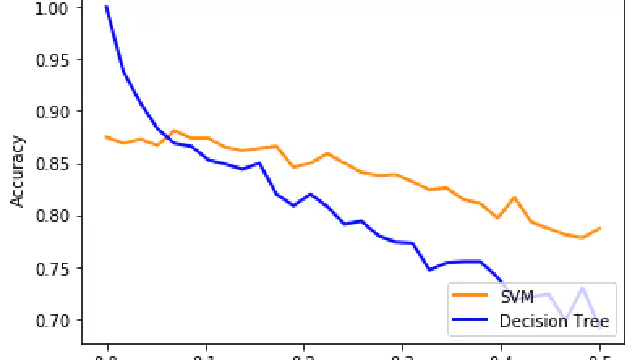
How can you be sure that your models continue to work in the future? One simple method of testing robustness is to add some noise to the test data. From the response we can infer whether the model is stable or unstable. See this Python Notebook to find out more.
To be able to create models, you need to know how to compare them. In this python notebook you will learn how to compare models quantitatively. I.e. create summary statistics for your model's performance.
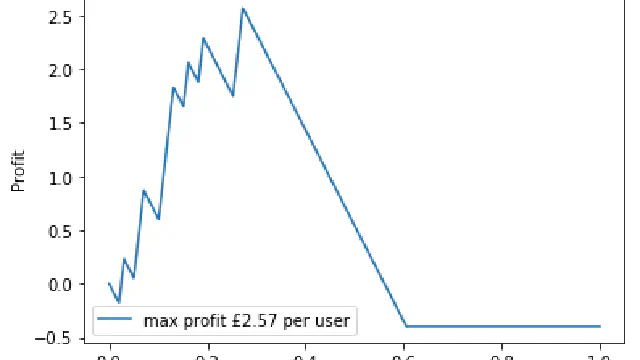
You should always try and visualise your data science. Especially when measuring model performance because this allows you to easily compare and spot errors with models. This Python Notebook shows you visualise model performance.
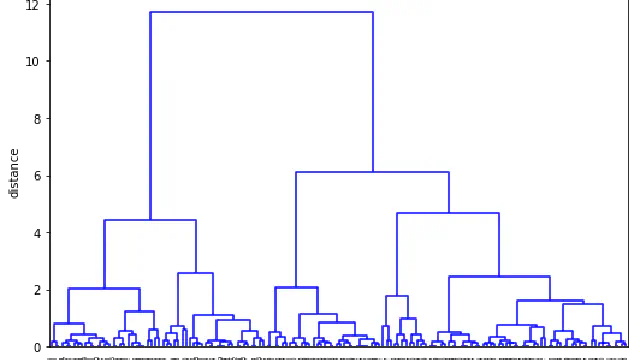
Often data is produced by a process that has some natural hierarchy. If you have a clustering problem where this is true, hierarchical clustering works really well. Find out more in this Python Notebook.
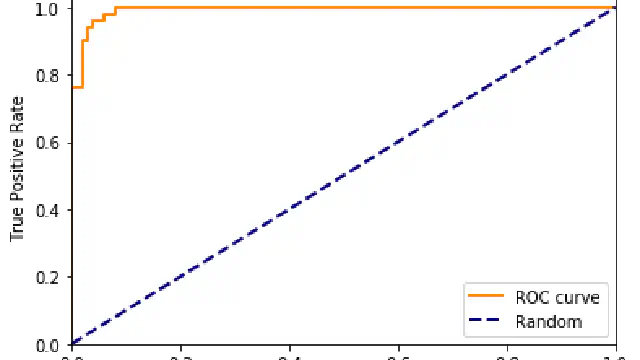
Probabilistic models are great at promoting good science. I.e. we're trying to model features to predict outputs. In this Python Notebook you will learn how to calculate bayes rule and use a naive bayes classifier.
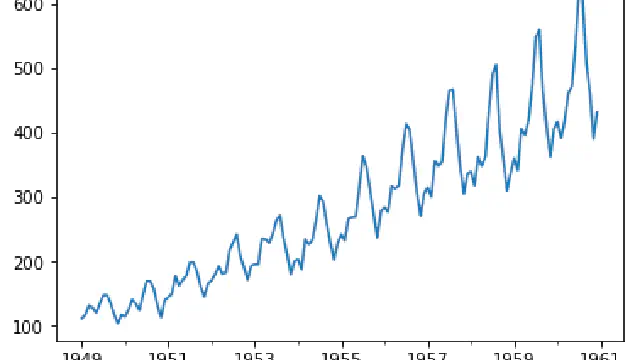
A quick Python Notebook to show you how to use statsmodels to detrend seasonal data.
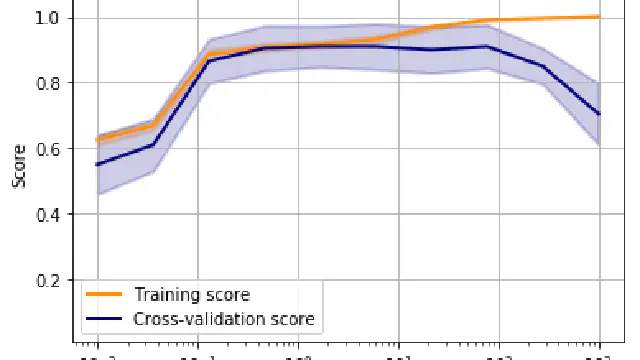
Most of the time you have too many dimensions to simply plot the decision boundary of a classifier. This workshop investigates other ways to visualise under and overfitting in high-dimensional datasets.
Case studies and industry analysis from our team. No hype, roughly monthly.