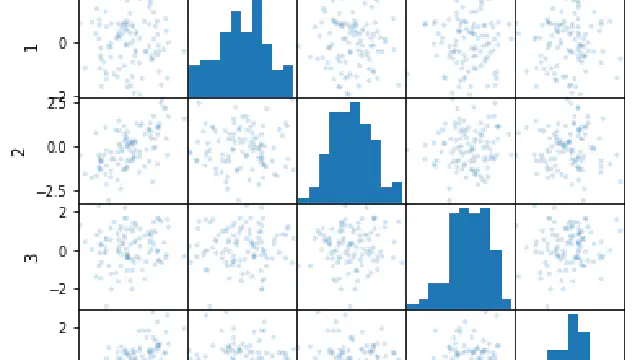
Why Correlating Data is Bad and What to do About it
A Python Workshop explaining why correlating data is bad and what to do about it.
A Python Workshop explaining why correlating data is bad and what to do about it.
A gentle introduction to Python and Jupyter Notebooks.
A Python Workshop introducing the concept of entropy.
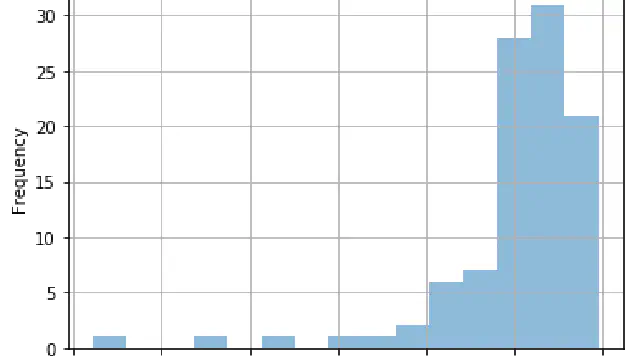
A Python Workshop showing you how to create histograms and how to invert skewed data.

A Python Workshop explaining and deriving a decision tree.
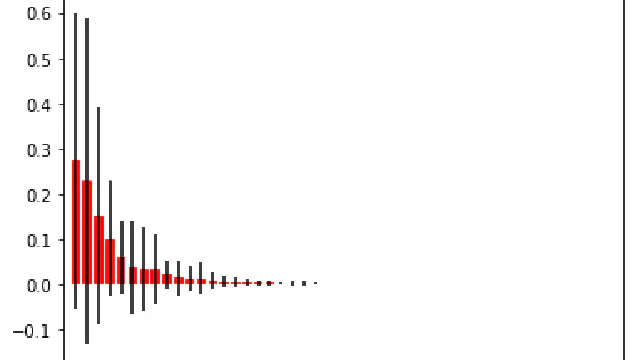
A Python Data Science Workshop providing an example of working with and cleaning loan data.
The 5-Whys is a simple technique to get to the root cause of a problem. Find out how it works.

A workshop explaining and demonstrating probability distributions.
It's a fundamental question. Why do we use the standard deviation? Is it the best in all circumstances? Maybe not.
A workshop explaining and demonstrating the mean and standard deviation.
Case studies and industry analysis from our team. No hype, roughly monthly.