Visualising Underfitting and Overfitting in High Dimensional Data
- Published
- Author

Visualising Underfitting and Overfitting in High Dimensional Data
Welcome! This workshop is from Winder.ai. Sign up to receive more free workshops, training and videos.
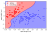
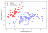
In the previous workshop we plotted the decision boundary for under and overfitting classifiers. This is great, but very often it is impossible to visualise the data, usually because there are too many dimensions in the dataset.
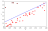
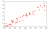
In thise case we need to visualise performance in another way. One way to do this is to produce a validation curve. This is a brute force approach that repeatedly scores the performanc of a model on holdout data for each parameter that you specify.
Read more