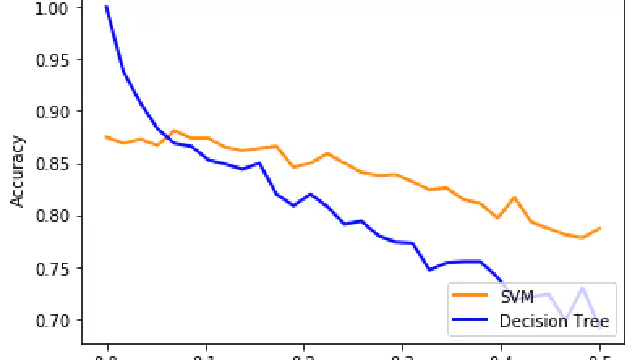
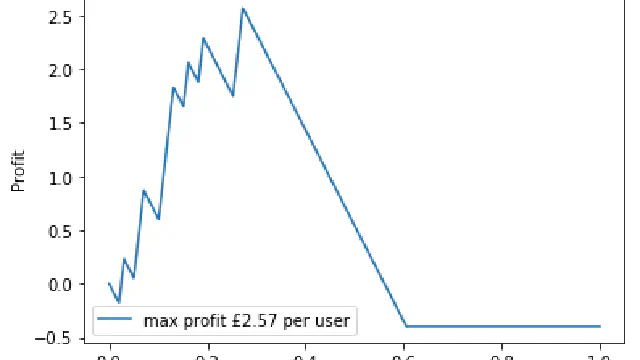
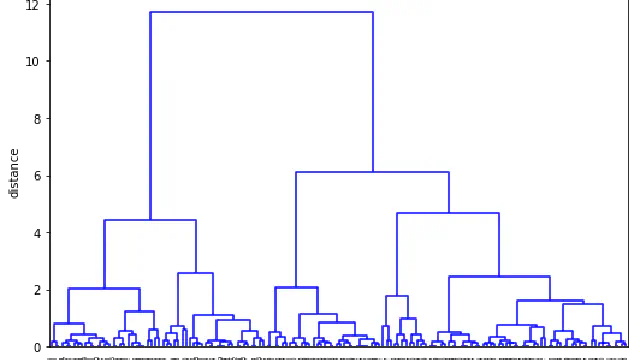
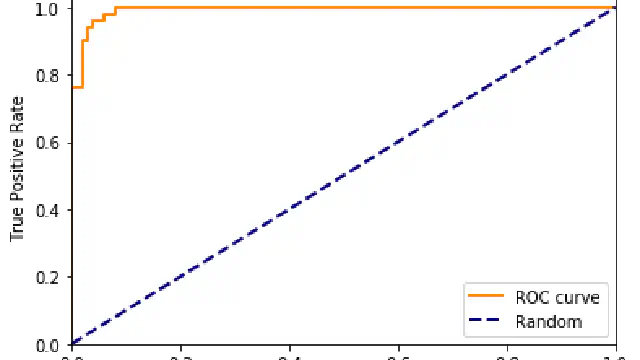
202: Segmentation For Classification
In this video we discuss segmentation, a very simple way of generating a predictive classification model given some data. We'll see later how this is the basis for a fundamental but very powerful machine learning algorithm.