503: Visualising Overfitting in High Dimensional Problems
- Published
- Author
Validation curve
One simple method of visualising overfitting is with a validation curve, (a.k.a fitting curve).
This is a plot of a score (e.g. accuracy) verses some parameter in the model.
Let’s compare the make_circles dataset again and vary the SVM->RBF->gamma value.
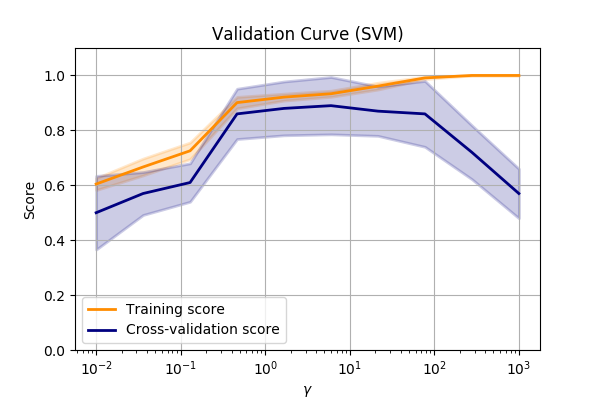
???
Performance of the SVM->RBF algorithm when altering the parameters of the RBF.
We can see that we are underfitting at low values of \(\gamma\). So we can make the model more complex by allowing the SVM to fit smaller and smaller kernels.
Read more