
Machine Learning Presentation: Packaging Your Models
This talk discusses common ways to package your machine learning models. Learn about best practice and the current state-of-the-art.
 Dr. Phil Winder
/
1 min
Dr. Phil Winder
/
1 minThis talk discusses common ways to package your machine learning models. Learn about best practice and the current state-of-the-art.
Dr. Phil Winder
/
1 min
Learn the difference between lineage and provenance. Discover the different strengths of lineage. Find out how you can decompose your AI projects to make your machine learning models more repeatable, understandable, and robust.
Dr. Phil Winder
/
1 min
Kubeflow is an incredible project, and Kubeflow pipelines have become the defacto open-source pipelining solution for machine learning pipelines. But it's not good enough and we need to move past it. Learn why and how.
Dr. Phil Winder
/
11 min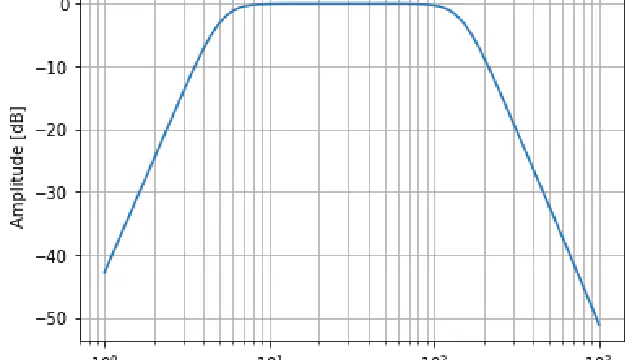
Learn about how to implement the fastest time-series filters in Python.
Dr. Phil Winder
/
7 min
A little bit of research turned into a rant asking why is it so difficult to use two of the most popular Data Science libraries together? And a little bit about Scikit Pandas.
Dr. Phil Winder
/
5 min
Where there are large numbers of features it becomes hard to visualise data and can cause problems with computational complexity. This python tutorial introduces dimensionality reduction and principal component analysis.
What to do when you need to perform a distance measure for a nearest neighbour like algorithm, but you have a large dataset?
Feature scaling and the type of distance metric used in nearest neighbour algorithms has a big effect on performance. This data science training video talks about this and other nearest neighbour tips and tricks.
The nearest neighbour algorithm can also be used for classification and regression purposes. Find out how in this training video.
The idea of similarity transcends problem boundaries. From recommendations to classification, learn how the nearest neighbour algorithm is not only useful but also very simple.
Case studies and industry analysis from our team. No hype, roughly monthly.