Part 5: How to Monitor a Large Language Model
by Natalia Kuzminykh , Associate Data Science Content Editor
The adoption of ChatGPT as a replacement for various machine learning tasks is rapidly increasing. What is regarded as a model today might simply be a prompt-response interaction tomorrow.
Yet, even as more businesses integrate Large Language Models into production, challenges around performance and task assessment persist. In addition, LLMs introduce their own unique set of constraints that are important to understand and monitor. Careful monitoring is critical to maintaining your applications and ensuring the safe and efficient use of models.
In this article, we’ll explore the essential metrics for monitoring ChatGPT applications.
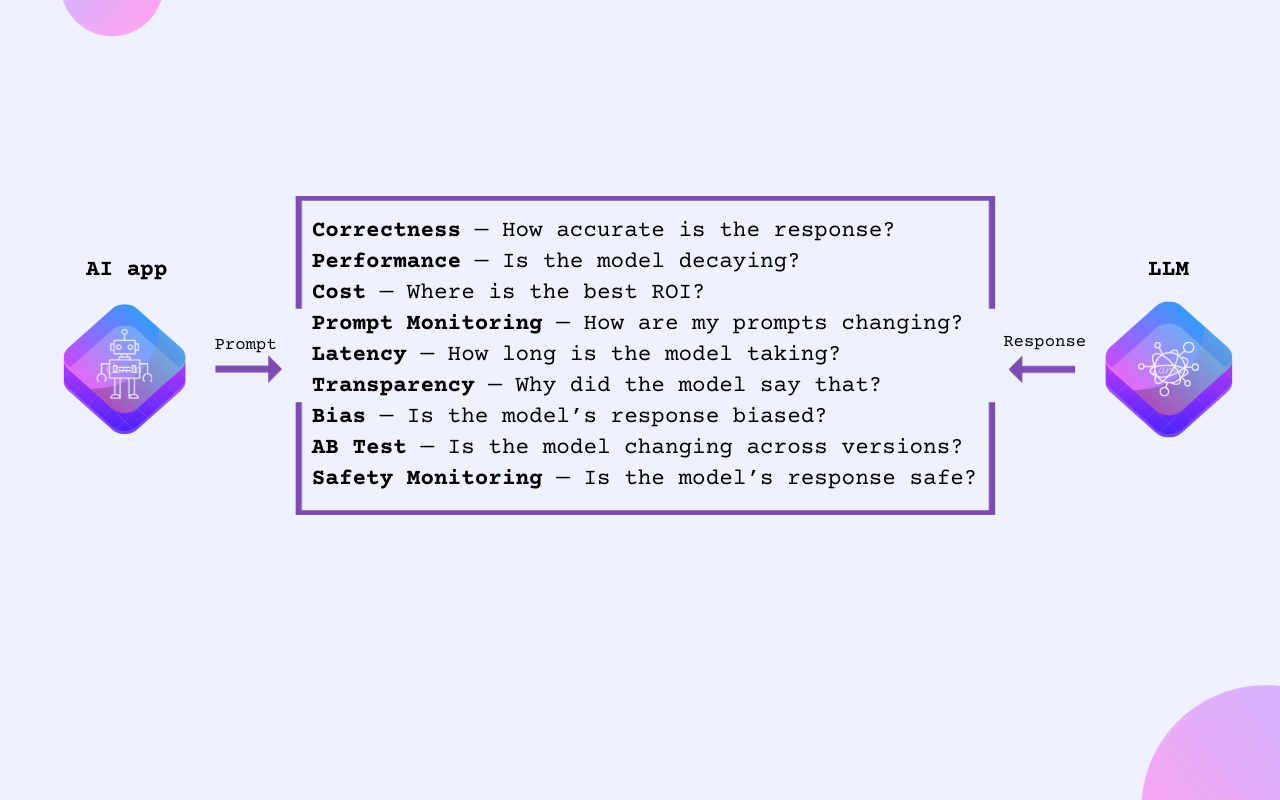
LLM Evaluation
While traditional ML models rely on metrics like accuracy, F1 score, precision, and recall for evaluation, LLMs introduce nuances that these conventional metrics may overlook.
For instance, accuracy can provide feedback on the correctness of the next word prediction, but it doesn’t consider the confidence of a prediction. If a model already knows it is making a low-probability prediction, then the model shouldn’t necessarily be penalized. This is where metrics like perplexity are useful. They offer a more granular understanding of the model’s predictions by assessing the probability distribution of its word choices.
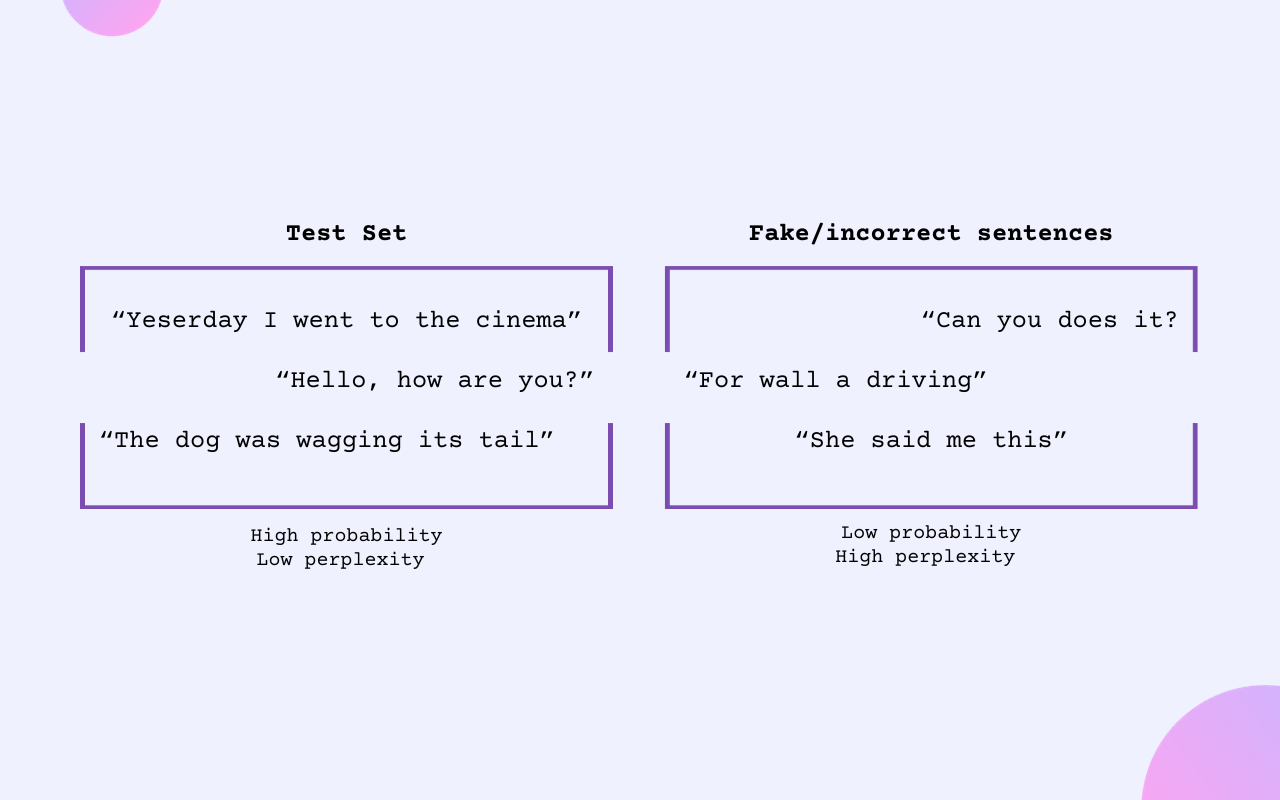
Examples of perplexity evaluation.
To effectively monitor LLMs, professionals employ several evaluation methods, each tailored to the specific characteristics of LLM output:
Classification and Regression Metrics share strong similarities with traditional methods. Thus, when a ChatGPT model tackles numerical scoring or classification tasks, its output evaluation follows the same procedures as ML models.
Some text-centric metrics attempt to measure performance even when reliable ground truth data is absent. Determining whether these methods are acceptable depends on the use case.
In this context, perplexity is a crucial metric. It measures the model’s ability to correctly predict the probability of the next word and can be interpreted as how well it understands its training text. A rule of thumb here is that a lower perplexity score indicates a higher confidence in generated outputs, showing better adaptation to the training text’s nuances.
To adopt a more advanced technique, developers can also consider leveraging embeddings analysis in search of irregular patterns. Tools such as Arize can streamline this process, providing a 3D graphical representation of extracted embeddings. Furthermore, one can highlight and group them based on distinguishing factors such as gender, predicted type, or perplexity score. Doing so can uncover potential issues in your LLM application, offering a comprehensive view of both bias and explainability within your models.
Besides visual assessment, using an anomaly detection algorithm on embeddings can further improve the monitoring process. This analysis identifies outliers, strengthening the model by highlighting areas that require attention and adjustment.Evaluation Datasets are designed to compare text data to a predefined set of validated responses.
Two notable metrics in this domain are ROUGE and BLUE. For example, in language translation tasks, the ROUGE metric can help to compare a reference dataset with the results of the assessed LLM. This comparison allows for the calculation of various metrics, including relevance and accuracy.
It’s important to note that there can be a disparity in the performance when testing your pipeline against a standard benchmark, like Beir, and actual production data. This is often due to distribution shifts between the datasets. Additionally, creating an accurate and reliable “golden test set” is both resource-intensive and time-consuming.Evaluator LLMs might appear somewhat unconventional for use as an assessment tool. However, an increasing number of companies are recognizing their potential and are integrating them into different assessment processes.
Take, for example, the Toxicity metric. It employs the Evaluator LLM (i.e. roberta-hate-speech-dynabench-r4) to determine the toxicity level of the ChatGPT model output. The same standards as set out above for evaluation datasets apply here, with Evaluator LLM results being treated as a reference.
Moreover, Arize experts suggest using Evaluator LLMs for binary classification rather than numerical scores, noting that binary labelling is simpler and more effective. Read their guideline.
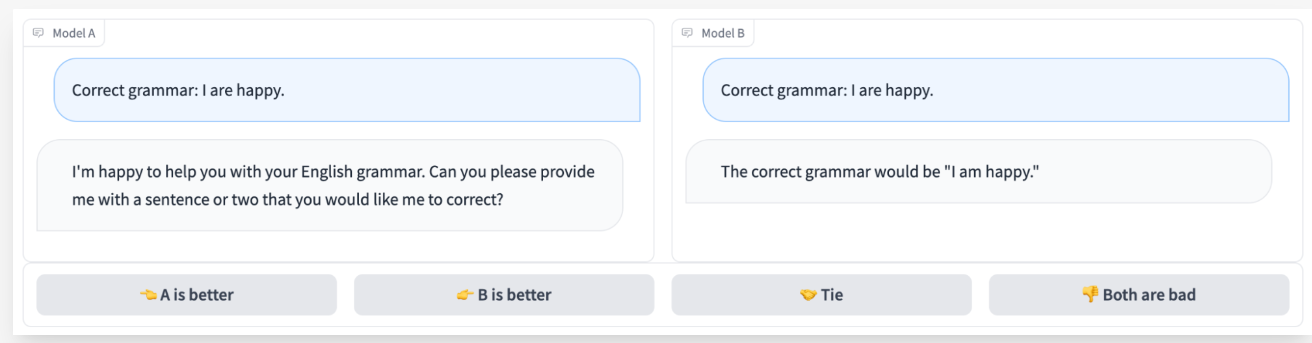
The evaluator simultaneously assesses both models to determine which one performs better.
- While measurable metrics are essential in software documentation and marketing, don’t overlook the value of human feedback both in the initial stages and during the final evaluation. Leveraging LLM observability software can simplify this process with user-friendly user interfaces. Furthermore, manual analysis of just 50 to 100 input prompts can offer invaluable insight into your product’s performance. Human feedback can also be fed back into the model to improve its performance via RLHF.
Tracking LLMs
Given various potential evaluation metrics, our next challenge is to effectively track model performance and behaviour in real-time.
Tracking is not just about collecting data; it is a strategic approach to understand how the model interacts with users, identify areas for improvement, and proactively address issues before they become major problems.
ChatGPT-like models consume every piece of information — whether you’re feeding it an instruction or receiving a response from — as tokens. So, if you ask it a question, the tokens used in framing your question (input) and the tokens used by the model to generate a response (output) together count towards the total tokens used in that interaction.
Why does token efficiency matter? Two primary reasons: cost and performance:
First, when using these models on cloud platforms or API-based services, you’re often charged based on the number of tokens you consume. Hence, efficient use ensures that you’re getting the most out of your investment.
Second, there’s an upper limit to how many tokens a model can handle in a single request. By keeping a close watch on token usage, you prevent running into errors or issues related to surpassing this limit.
Time is another invaluable resource that deserves our attention. It’s important to value your users’ time – faster products are more profitable. This concern can be addressed by tracking latency.
While latency serves as an indicator of the duration between a user’s request and the model’s reply, monitoring the number of requests your model can handle per second (i.e. throughput) is crucial in high-traffic scenarios where rapid processing of a large volume of requests is a necessity.
Furthermore, time can be a factor that negatively influences the data distribution in your LLM, causing a drop in model efficiency. Thus, tracking for drift between your ChatGPT model’s inputs and outputs is crucial, as changes can signal early adjustments due to user behaviors or environmental shifts.
Monitoring LLMs
Using evaluation and tracking as a base, monitoring serves as the crucial balance between performance and reliability. It represents AI maturity in a business and helps to deal with evolving demands.
Now, let’s break down the core elements of monitoring to help you build a robust program that protects your users and brand:
Functional Monitoring: Starting with functional monitoring, it’s essential to observe primary aspects like the number of requests, latency, token usage, costs, and error rates.
User Prompt Monitoring: Once these basics are in place, the focus should shift towards monitoring user prompts. This includes testing text-based metrics like perplexity and using Evaluator LLMs to examine potential issues in the model’s response. This stage also highlights the necessity of vigilance against adversarial attacks, especially those involving malicious prompt injections. Comparing user inputs with known adversarial prompts and leveraging evaluator LLMs can help in detecting and classifying malicious activities.
Response Monitoring: Following prompt surveillance, the monitoring program should assess LLM responses. Here, the emphasis lies in understanding whether the LLM’s outputs align with the expected content or diverge from the anticipated topics. Take, for example, relevance: if the LLM starts providing irrelevant content, it may be a sign of “hallucination”. While not every metric demands daily oversight — some might suffice with monthly or quarterly checks — regular vigilance is essential for toxicity and harmful outputs. Periodically testing the LLM against reference datasets can also help track accuracy over time, identifying any drifts in performance.
User Interface: Any comprehensive monitoring program should include a user interface (UI) for visualizing metrics over time. An efficient UI not only presents basic time series graphs but also enables in-depth analysis of alert trends and, potentially, the underlying causes behind them.
Alerting: With the underlying metrics in place and the ability to view them, the final piece of the puzzle is to integrate an alerting solution that notifies you of any issues. This can be done by setting up alerts for specific metrics or by using anomaly detection to identify unusual patterns in the data.
Final Thoughts
As businesses continue to integrate LLMs for various tasks, it’s important to ensure their effectiveness and compliance with regulations. Early detection of performance issues through continuous monitoring can help tailor these models to specific business needs, optimizing their usefulness and relevance in a highly dynamic market environment. Additionally, ethical and regulatory concerns must be considered as these models rapidly advance.
By prioritizing monitoring and evaluation, businesses can maintain their reputation and competitiveness in the marketplace. Overall, the pivotal role of LLMs in enhancing customer interactions and data-driven strategies, makes monitoring and evaluation indispensable for mitigating risks and sustaining a competitive edge.