Pachyderm ❤️ Spark ❤️ MLFlow - Scalable Machine Learning Provenance and Tracking
by Enrico Rotundo , Associate Data Scientist
This article shows how you can employ three frameworks to orchestrate a machine learning pipeline composed of an Extract, Transform, and Load step (ETL), and an ML training stage with comprehensive tracking of parameters, results and artifacts such as trained models. Furthermore, it shows how Pachyderm’s lineage integrates with an MLflow’s tracking server to provide artifact provenance.
This text is a shortened blog post based on the more comprehensive and interactive notebook available on the code repository in GitHub. Please feel free to check out the repository to install and run the demo setup on your machine.
Pachyderm is a data science platform that combines Data Lineage with End-to-End Pipelines.
Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning (ML) on large clusters as well as a single-node machine.
MLflow is an open-source platform for managing the machine learning lifecycle and tracking experiments.
By reading this post you will learn how to:
- Use Pachyderm’s pipelines to engineer and ETL your data at scale.
- Employ Pachyderm in concert with MLflow and Spark to train an ML model and track related artifacts.
- Build a bidirectional lineage link between Pachyderm and MLflow to retrieve model provenance.
Therefore, I will demonstrate an example of ML fraud detection based on a synthetic financial dataset with a focus on the end-to-end pipeline rather than on model statistics and performance.
Add Raw Data to Pachyderm
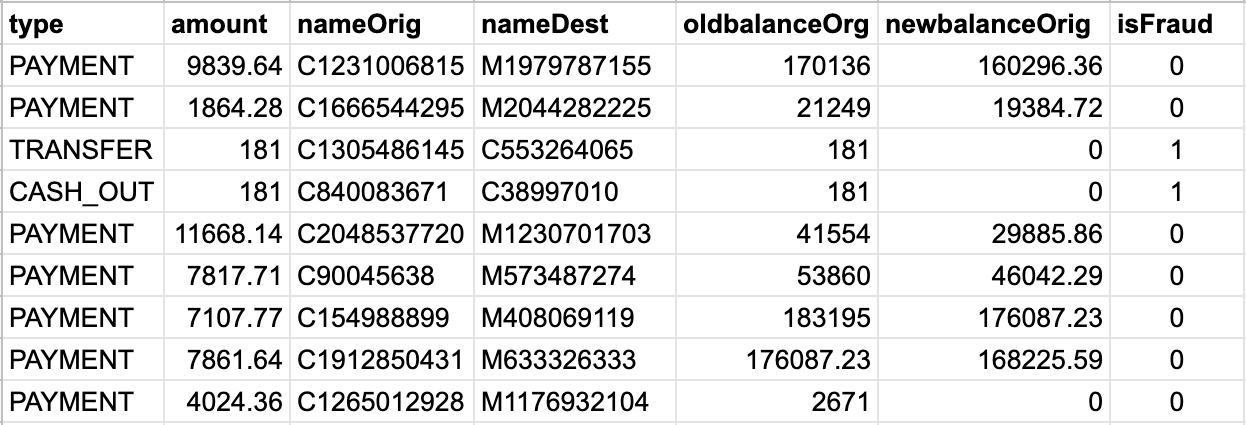
Let us first take a look at the excerpt of the raw data depicted in the figure below.
It is a financial fraud dataset from Kaggle where each record represents a transaction between customers.
For brevity, I am omitting some of the columns but what is important here is the rightmost one, which is going to be my ground truth, indicating whether a transaction was indeed fraudulent.
Pachyderm stores data in repositories, these locations work similar to Git, in fact, you can commit data to a specific branch.
Below I create a data repository and populate it with the raw dataset so I push the data file to a location named raw_data on the master branch.
!pachctl create repo raw_data
!pachctl put file -r raw_data@master -f PS_20174392719_1491204439457_log.csv
The operation above is snapshotted into a commit whose hash is f18e3cb3496e4a1fa853f05cb357dc62, this is shown in the snippet below.
In Pachyderm, every change to the content of the repository generates a new commit, effectively providing version control for data and what I like about it is that it is completely automated and transparent to the user.
!pachctl list commit raw_data@master
REPO BRANCH COMMIT FINISHED SIZE ORIGIN DESCRIPTION
raw_data master f18e3cb3496e4a1fa853f05cb357dc62 Less than a second ago 470.7MiB USER
Split Data per Customer
Designing an effective ML training pipeline likely entails turning lots of raw data points into a dataset that represents the business objective at stake.
In a context where each user generates a multitude of signals, it is often sensible to aggregate such information into smaller pieces.
Having said that, I am now in a stage where my data blob is stored on the cluster as a single file.
However, generally speaking, most distributed systems work better when dealing with chunked files, this way the cluster’s hosts can split the work as process bits of data independently.
With that in mind, I create a Pachyderm pipeline to split data per customer so that it produces a set of individual files, each storing the transactions of that specific user.
This not only helps with sharding the subsequent processing, but it is also the very first step of my data preparation.
Below I use a python script run in the pipeline to output a set of sharded files.
If you are not familiar with this format I refer you to the official docs, anyway, I will just mention the pipeline runs a command (see cmd field) from within a Docker image (see image field) that I have prepared in advance.
The output data ends up in a new repository named after the pipeline itself (i.e. split_data).
%%writefile pipeline_split_data.json
{
"pipeline": {
"name": "split_data"
},
"description": "A pipeline splits raw datasets producing a chunk per customer.",
"transform": {
"image": "winderresearch/pachyderm-split-csv:0.1.0",
"cmd": [
"python",
"/split-dataset.py",
"/pfs/raw_data/",
"/pfs/out/",
"--subsample",
]
},
"input": {
"pfs": {
"repo": "raw_data",
"glob": "/*"
}
}
}
!pachctl create pipeline -f pipeline_split_data.json
The state of the processing job shown below confirms it has terminated successfully!
!pachctl list job -p split_data
PIPELINE ID STARTED DURATION RESTART PROGRESS DL UL STATE
split_data da4117bc7de24fbea0d13dd947e29d6e 31 seconds ago 30 seconds 0 1 + 0 / 1 470.7MiB 9.897KiB success
Let us now inspect the content of the output repository.
As expected there is a set of individual CSVs, note here that the file names represent their respective unique customer ids.
!pachctl list file split_data@master
NAME
/1055929140.csv
/1083110206.csv
/1141876486.csv
/1206877978.csv
/123757418.csv
/1248586428.csv
/1282235003.csv
/1359467526.csv
/1419296243.csv
Aggregate Customer Data Points
The scenario at this point has two dimensions, one being a potentially large number of customers (i.e. many CSVs) and the second being tons of records for each customer (i.e. large CSVs).
Luckily, Pachyderm is perfectly capable of handling the former by distributing data among workers. I achieve that in the pipeline below by creating a pool of 8 workers with parallelism_spec (more about it in the official docs).
Furthermore, to control how Pachyderm distributes shards across workers, I set the input.pfs.glob spec to /*, which is a specific glob pattern that exposes each CSV to a separate unit of work.
For more details on how glob patterns work, I point you to the related docs.
The latter dimension is addressed by using Spark to process each customer’s data separately.
Apache Spark is known for its ability in dealing with potentially humongous datasets hence it is well suited for this task.
In detail, the Spark script run by this pipeline collapses a customer’s data into an aggregated form by averaging across all of their transactions.
%%writefile pipeline_etl.json
{
"pipeline": {
"name": "etl"
},
"description": "A pipeline maps a PySpark aggregation function over dataset shards.",
"transform": {
"image": "winderresearch/pachyderm-spark:0.1.0",
"cmd": [
"spark-submit",
"/root/etl.py",
"/pfs/split_data/",
"/pfs/out/"
]
},
"parallelism_spec": {
"constant": 8
},
"input": {
"pfs": {
"repo": "split_data",
"glob": "/*"
}
}
}
!pachctl create pipeline -f pipeline_etl.json
!pachctl wait commit etl@master
!pachctl list job -p etl
PIPELINE ID STARTED DURATION RESTART PROGRESS DL UL STATE
etl d8a1fcf32c5c42b5a331ce442c474533 7 minutes ago 7 minutes 0 50 + 0 / 50 9.897KiB 10.01KiB success
This pipeline results in a set of folders, named after the related customer id, each containing a CSV file with the aggregated records.
!pachctl list file etl@master
NAME
/1055929140/
/1083110206/
/1141876486/
/1206877978/
/123757418/
/1248586428/
/1282235003/
/1359467526/
/1419296243/
Train a Fraud Detection Model
Now that I have prepared my dataset it is finally time for ML to kick in.
I am ready to train a fraud detector, the pipeline below uses MLlib, Spark’s ML library, to load the entire dataset and fit a decision tree to classify frauds.
Note that for the sake of brevity, in this demo I don’t dive into model performance and tuning.
A decision tree is a simple but powerful ML model type which supports extended explainability, which is one of the reasons for its popularity in the financial sector.
A tree structure is composed of leaves representing class labels, and branches representing conjunctions of features that lead to those class labels, for further details check this article.
Throughout the training run, the pipeline below uses MLflow for tracking model hyperparameters, performance metrics and artifacts (i.e. serialized model).
The training script uses MLFlow python client to collect those items and push them to an MLflow server.
Important
Generally speaking, Spark-MLlib works fine for simple ML models and within the scope of this article that is just enough. However, it falls short when the problem at stake requires a more complex modelling technique such as deep learning. Fortunately, Pachyderm can run any ML framework of your preference, in fact, in the pipeline below I could have just used Tensorflow, PyTorch, Scikit-learn, etc.
%%writefile ml_train.json
{
"pipeline": {
"name": "ml_train"
},
"description": "A pipeline runs Spark-MLlib to train a machine learning fraud detector over the given dataset.",
"transform": {
"image": "winderresearch/pachyderm-spark:0.1.0",
"cmd": [
"spark-submit",
"/root/ml-train.py",
"/pfs/etl/",
"/pfs/out/"
]
},
"parallelism_spec": {
"constant": 1
},
"input": {
"pfs": {
"repo": "etl",
"glob": "/"
}
}
}
!pachctl create pipeline -f ml_train.json
!pachctl list job -p ml_train
PIPELINE ID STARTED DURATION RESTART PROGRESS DL UL STATE
ml_train baaaad7a5b1c4c2e8a79cbe8beaad1c2 57 seconds ago 56 seconds 0 1 + 0 / 1 10.01KiB 0B success
Inspect Provenance
The ML training has been completed and pushed artifacts to MLflow.
The snippet below runs a helper script that shows the Pachyderm commit and related MLflow run id.
Let us take a moment to understand what is shown below.
To keep full provenance, the training pipeline writes the MLflow run id (i.e. 53eafaf4f39b4c1485957db02b7ee5fd) to a file in the output repository (i.e. /pfs/out/).
This results in a Pachyderm commit (i.e. baaaad7a5b1c4c2e8a79cbe8beaad1c2) that has effectively been linked to an MLflow run!
!./get_provenance.sh
File generated by the training pipeline (represents an MLflow run id) at "ml_train@master":
NAME TYPE SIZE
/53eafaf4f39b4c1485957db02b7ee5fd file 0B
Pachyderm commit at "ml_train@master":
REPO BRANCH COMMIT FINISHED SIZE ORIGIN DESCRIPTION
ml_train master baaaad7a5b1c4c2e8a79cbe8beaad1c2 21 minutes ago 0B AUTO
See the screenshot below, MLflow web UI allows you to inspect parameters, metrics and navigate through the artifacts folder where the serialized model is located.
It is not depicted here but it also catalogs the experiment runs for you on a dedicated page.
All that is automatically tracked by MLflow, all you need to do is add a few lines of code to your training script, et voilà!
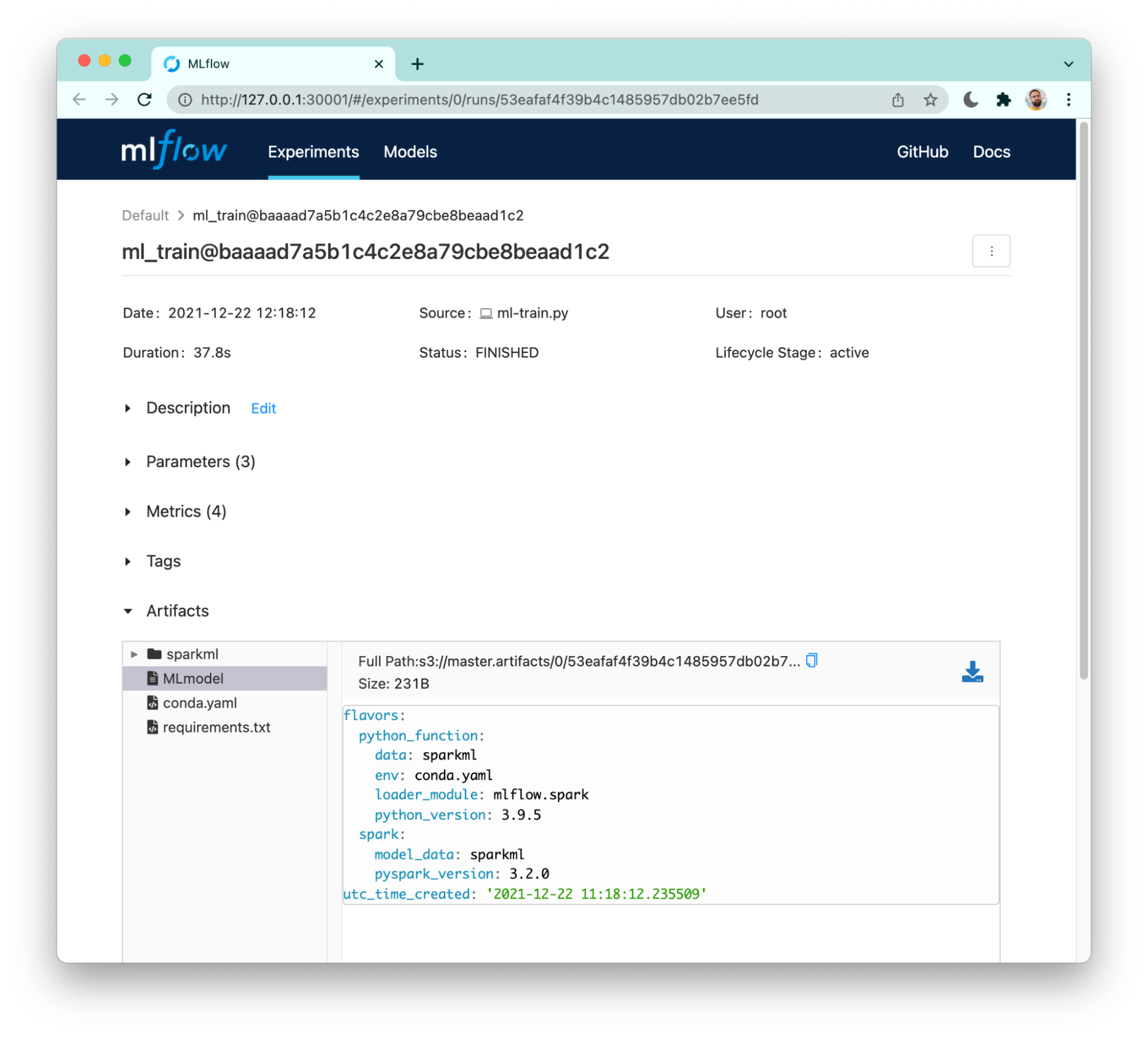
I have showcased how artifacts are linked from Pachyderm to MLflow.
Since provenance is bidirectional, let me now briefly explain how to go the other way.
Let us suppose I am given an MLflow run id (e.g. 53eafaf4f39b4c1485957db02b7ee5fd) and I would like to find the corresponding Pachyderm commit.
There are a number of ways to script this, for brevity I simply list files backwards into my repository history.
!pachctl list file ml_train@master
NAME TYPE SIZE
/53eafaf4f39b4c1485957db02b7ee5fd file 0B
In this case, the latest commit is exactly the one that holds the run id I am looking for.
Hence, I just fetch the related Pachyderm commit (i.e baaaad7a5b1c4c2e8a79cbe8beaad1c2).
!pachctl list commit ml_train@master
REPO BRANCH COMMIT FINISHED SIZE ORIGIN DESCRIPTION
ml_train master baaaad7a5b1c4c2e8a79cbe8beaad1c2 23 minutes ago 0B AUTO
ml_train master a46164cacea4815a5608099ff17b49d2 42 minutes ago 0B AUTO
Important
Thanks to Pachyderm’s provenance model, it is feasible to track lineage upstream up to the initial source.
In other words, you will be able to tell which commit in the raw data repository originated a specific version of a trained ML model.
Even more powerful is the capability of rolling back to a previous version of an ML model by a single command and without using virtually any computing.
This scenario is described in depth this other article we published earlier.
All that is extremely valuable when your organization wishes to hold control over its deployed models and be able to respond quickly to unforeseen changes in the data.
Summary
In this article, I have presented how to:
- Use Pachyderm’s pipelines to engineer and ETL your data from a raw format to a usable dataset.
- Employ Pachyderm in concert with MLflow and Spark to train an ML model and track related artifacts.
- Build a bidirectional lineage link between Pachyderm and MLflow to retrieve model provenance.
Pachyderm is the backbone storage and pipelining component, it is used for artifacts lineage and to manage processing jobs.
Spark is used to pre-process a dataset as well as for training an ML model.
MLflow comes in handy to track and display a variety of aspects composing an ML training run such as parameters, metrics and artifacts such as a serialized model.
Of course, Winder.AI is ready to help you improve your ML workflows through a combination of MLOps consulting and AI consulting.
References
- Reproducible and interactive version of this article in GitHub repository
- Pachyderm’s views on data lineage and why it matters
- MLflow introductory post
Credits
This work was funded by Pachyderm, Inc.