LLMs: RAG vs. Fine-Tuning
by Dr. Phil Winder , CEO
Interest in the use of large language models (LLMs) has ballooned in our recent AI consulting projects because they are applicable to a wide variety of AI problems. Our LLM consulting services help organizations determine the best approach for leveraging proprietary data. But most use cases require the use of proprietary data. What’s the best way of leveraging private or local data in LLMs?
Two approaches have gained traction. Retrieval augmented generation (RAG), which is best summarised as retrieving data from a data repository to place in the context window of an LLM. Or fine-tuning LLMs, which is a process that alters how LLMs respond to inputs. Both are capable of ingesting “knowledge”. But which should you use? And why?
This video will answer these questions and more. Learn how to decide the best architecture for your domain-specific problems. And see a variety of examples to help understand the differences. More notes are available below.
Download SlidesThe following transcript has been lightly edited for clarity.
Introduction
As an AI agency, we’re working with a number of clients incorporating private knowledge into LLMs.
One of the key questions in those projects is: what’s the most efficient way of giving the LLM the domain specific knowledge required to do its job effectively.
In this talk going to attempt to demystify the differences between fine-tuning and RAG. To do this I’ll spend a little bit of time explaining how LLMs learn and why RAG presents another opportunity to do the same thing.
Question answering on private data is the top use cases for LLMs, so I will be focusing on this. The first half is more for beginners, the second half gets more technical.
At the end I’ll present recommendation for when you should use RAG when you should use fine-tuning.
To reduce the scope of this presentation I will not be talking about implementation details, nor will I be talking about architectures. RAG in particular, benefits from significant architectural flexibility, which has led to a wide range of different implementations. You can learn more about that in a dedicated presentation about RAG architectures.
Large Language Models Provide

Large language models or LLMs provide you with a model that is very good at predicting the next word, on average. Contained within those words is knowledge. I’ll leave it to the philosophers to define the word knowledge. But as an example, LLM’s tend to be fuzzy and therefore struggle with logic.
The reason for this is that the training data contains all sorts of contradictions. Any LLM should know one plus one is two. It is a basic test that all LLMs have to pass. But here is an example I found from a Black Eyed Peas song that clearly tells the LLM that one plus one might not be two. It could be three. It could be four. It could be things that are not even numbers. I could be a swearword on the end.
This is a very small example of what the training data looks like. Remember that LLM’s are machine learning models trained in a supervised manner. The goal of this model is to predict the next word.
Obviously, the result is going to be fuzzy. But LLMs compress a lot of text, about a lot of different topics. Which makes it useful and knowledgeable.
Internalised knowledge is the primary use case for LLMs. But it turns out that they’re also really good at representing style and infusing concepts into the writing. That’ll be important when we come back to the recommendations later.
Finally, LLM’s are typically imbued with a certain set of aligning principles from the authors. Some attempt to apply ethics, or rules, or some attempt to make the LLM more useful for particular tasks. Either way this could be considered a form of style.
Large Language Models Do Not Provide
However LLMs do not provide the following.
They do not incorporate live data. For example they can’t tell you when the next train arrives. Or if you are in the UK, if it will ever arrive.
They do not provide problem specific data. For example they don’t know how to double check that you have a passport when you want to book a flight.
They don’t contain domain specific terms. For example, it doesn’t know what your product is called (unless you’re Microsoft).
And finally, the big one, they don’t contain any private or proprietary data. (Supposedly; that’s what OpenAI says anyway) For example it does not know about your company handbook.
So the question is how do we get this information into the LLM.
How LLMs and RAG Use Knowledge

I was inspired by a Reddit post which talked about LLMs as idiots. So please meet these two idiots in the best fancy dress you’ve ever seen.
Imagine your company has sold some technology and a customer calls tech support.
Idiot one is a reasonable LLM, for example GPT.
Idiot two is a fancy database with the company manual, something like Google search.
A customer comes in and asks the question: “I placed my router in the microwave, is the internet is broken?”
LLM Thinks
Idiot 1 thinks, hmm, I’m an LLM. I’m have some pretty good general knowledge.
- I recall that microwaves and wifi use similar parts of the electromagnetic spectrum.
- Microwaves have faraday cages in them to stop humans from melting themselves.
- And I know that the internet is a distributed network.
My answer:
The internet is not broken. The faraday cage is blocking millimeter radio waves.
RAG Thinks
Idiot 2 thinks, “hmm. Let me search the manual.
- The word place is in there. They must be talking about placement. Let me return the words for that segment of the manual.
My answer:
Place the router in an unobstructed position, away from walls.
Together is Better
The point of all this is that neither idiot really answered the question.
Idiot one provide some of the facts. Indeed it is unlikely that the user broke the Internet. But from the perspective of the user the Internet is not working.
Idiot too almost gets there by suggesting better placement of the router. But it doesn’t mention anything about microwaves because they aren’t mentioned in the manual.
So the true answer is probably some combination of those two. The Internet is not broken. But it’s not working for you because you’ve placed the router in a microwave take it out of the microwave.
Incidentally, I actually asked GPT 3.5 this question. It gave me a reasonable answer but with hugely sarcastic undertones.

I feel like that all of ChatGPTs outputs should have some sarcasm warning appended.
Adding Knowledge to LLMs
Let’s talk about how you can add new knowledge to your LLM.
What Does Fine Tuning Do?
Fine-tuning is the process of attempting to nudge the weights of the large language model to map new points in a high dimensional space.
Fine-tuning as it is normally done is indiscriminate. Different parts of the LLM represent different concepts. Fine tuning affects everything all at the same time.
By concepts I mean things like style like cadence, humour, the meaning of words, the ethics, goals, and yes, the knowledge.
This is the biggest issue with fine-tuning right now. All of the current research attempts to find better ways of nudging the weights to optimise for a measure of performance that isn’t particularly useful in an industrial context. I don’t particularly care if a new training method adds 1% accuracy if the LLM starts talking like Bugs Bunny. Or if I care only about adding domain-specific knowledge, I don’t want it to lose all of the other knowledge it already has.
This is just a fundamental limitation of the architecture of current LLMs. They would have to change quite significantly to tackle these issues.
What does RAG do?
So what does RAG do? First RAG stands for: Retrieval Augmented Generation.
In its simplest form, RAG retrieves data from an external source and passes it to the input of the LLM.
If if the context provides the answer, the LLM can give the answer to the user. If the answer is not in the context then it can’t. Or even worse, it guesses.
This makes it clear that the most crucial aspect of RAG is that you must retrieve the answer for the answer to be answerable.
It sounds silly, but this basically removes the burden of knowledge from the LLM and places it on the external retrieval mechanism.
You have a hugely powerful blob of knowledge and end up basically ignoring it. The LLM serves as something like a translator. Except that it’s more trying to explain, rather than translate. So explainer might be a better word.
Remember that LLM’s have not been fine-tuned to be explainers based upon context. That’s not their training data. This is another area of potential research.
In summary: LLMs bring fuzzy knowledge, RAG brings live data.
Myth: Fine-tuning can’t add knowledge
You will read that fine-tuning can’t add knowledge.
How do you think LLMs is got their knowledge in the first place. That’s right, by training.
And also it brings up the awkward conversation again of what is knowledge. When people are talking about fine-tuning, they’re not really talking about how training affects the underlying model.
They’re talking from the perspective of an individual use case. Typically that case is question answering. So we could probably rewrite that myth as: “for the purposes of question answering, fine tuning doesn’t work well.”
But that’s not entirely true either because I can demonstrate question answering working well on a dummy fine tune…
Thought Experiment – RAG
Imagine an experiment where you are comparing fine-tuning with RAG.
For RAG, literally give the answer in the context window of the LLM.
Here’s an example:
You are a professional customer service representative. You must answer questions based upon the following example question-answer pairs.
Q: I placed my router in the microwave, is the internet is broken?
A: No the internet is not broken. Please do not put your router in the microwave, that’s stupid.
The answer MUST NOT come from anywhere else.
Now, answer the following question:
I placed my router in the microwave, is the internet is broken?

This is what happens with ChatGPT. You see it’s almost used the answer I provided in the context. But it still couldn’t quite stop itself from making the answer a bit nicer.
Thought Experiment – Fine Tuning
For fine-tuning, we literally give the answer to a question in the fine-tuning training data. Here is an example QA pair. You can see the question from the human and the response we want to provide.
{
"conversations": [
{
"from": "human",
"value": "I placed my router in the microwave, is the internet is broken?"
},
{
"from": "gpt",
"value": "No the internet is not broken. Please do not put your router in the microwave, that’s stupid."
}
]
}
This is an example from one project we’ve developed, called Helix Cloud, that makes it easy to fine tune LLMs on your own data.
I passed in a single QA-pair and fine-tuned Mistral 7b. It has provided the answer I told it to, verbatim.

Two different methods, same answer, what’s going on here?
- RAG adds “knowledge” by providing the answer in the context.
- Dependent on how you present the data.
- Fine-Tuning adds “knowledge” via the fine-tuning data.
- Dependent on how you present the data.
- Both forms “add knowledge”
This was a demonstration of RAG answering the question using the context. The only requirement is that the LLM is smart enough to use that context. Since all LLMs have been trained to use a context to predict the answer, nearly any LLM will work.
The fine-tune example has been performed to maximise overfitting. This makes it almost become like a look-up table. When it’s given a question it spits out this exact answer. Typically this is not something you want to do but it’s a good example.
My point is this. You can’t claim that fine-tuning doesn’t add knowledge. It does.
For QA, Which is Better?
And of course, the answer is, it depends…
A fine-tuned model might:
- understand the domain better
- understand technical terms better
- use more precise language
- communicate in a style that is better suited to your domain
- be lower latency, because you don’t need as much context
- be lower latency, because you don’t need to call an external system
And if you can train the model on actual user QA pairs then:
- it might be able to answer the question but…
Visualize the LLM Prediction Manifold
Picture the actual manifold of the high-dimensional large language model in your mind’s eye. It’s like a sea with waves, except those waves are rotated and wrapped over itself.
Each point in that space represents a prediction for the next word given the previous words.

When you fine-tune, you’re altering the position of those waves. If you overfit, like we did in our previous example, you’re adding a spike out of the waves exactly where your question is. If you ask that question, you land perfectly on that spike and get the right answer. If the question is different by one key word, you hook left and you’re back on the sea of the underlying LLM (which probably can’t answer your question).
Generally you don’t want to overfit because you want the model to generalise over different phraseology. The key is training the LLM on representative and diverse user queries.
You can’t just feed in a document and say “answer this question”. You’ll never land on that spike.
What I’m saying here is that, just like in the rest of machine learning, if you training data does not represent production queries, you won’t get good results.
It’s the old adage, garbage in, garbage out.
If you truly want to fine-tune your LLM, You need to come up with a training dataset that contains every possible question that your LLM might face. Only then will you get 100% accuracy.
RAG vs. Fine-Tuning
Hopefully you I’m beginning to get an intuitive feel for how fine-tuning works. But let’s get back to the topic of conversation and talk about the performance differences over more representative data.
For QA Which Is Best?
If you go out and search for this answer and do your research you’ll find a wide range of different answers.
In general the consensus is that using RAG will perform better than fine tuning. You’ll also find a consensus that using RAG and fine-tuning together is even better.
However, you’ll also find a range of approaches that don’t make sense. This is an example paper from last year where they are fine tuning raw data.
Let me repeat that again. They are fine tuning on raw data. They training the model to predict the next word in their data. They then ask questions of that data. The model is never ever seen a question. It’s never seen an answer. It can predict what the next word is if you give it a few words of that document. But it can’t give you answers.
So obviously the results for fine-tuning are horrible. I’ve seen some suggest that the results are actually WORSE than the base model just left alone because you also trash some of its internalised knowledge.

A better example is this paper that attempted to generate question answer pairs based upon the raw data.
They demonstrated better performance with fine tuning, however RAG still produces overwhelmingly better results.
You have to be a bit careful when reading the numbers in these studies because they all use slightly different metrics and slightly different data to evaluate performance.
But you can compare the results. And you can see that RAG is orders of magnitude better than fine-tuning alone.
There’s a few other interesting results to come from this paper and one of them you can see here. The small model at the top tends to show surprisingly poor performance when using just RAG. But the fine tuning plus rag solution approaches the performance of the larger models.
This is a very small but fascinating result that might indicate that using fine-tuning and RAG together with small models can approach the best performance of larger models. So for some cases we are trying to optimise for performance, for example, this might be very useful.
RAG vs. Fine-Tuning: Recommendations

For pure question answering applications, the consensus is that RAG is better. I think this makes sense intuitively. You are taking advantage of the sophisticated retrieval capabilities that the LLM does not have. LLMs have not been trained to retrieve data. And you’re also taking some advantage of the raw power of the underlying LLM.
But fine tuning is still useful.
It’s useful for adding domain specific terms and language. This will add those final few percent to the performance metrics.
It’s useful for altering the style, things like, the cadence, the humour, the professionalism, the persona.
If you need to alter the function of the LLM, like adding function calling, or training the LLM to ignore irrelevant retrievals, fine tuning can help.
RAG also struggles in some scenarios, for example with massive contexts, or with retrievals that aren’t relevant. Fine tuning can help.
Other Interesting Findings
Now that we’ve identified that in general, RAG tends to performance better than fine-tuning, let’s dig into some of the more interesting findings.
Quality QA-pair Generation is Crucial
The literature online and in papers massively under-represents the challenge of QA-pair generation.
The effectiveness of fine-tuning, and indeed all model training, rests solely on the quality of the data.
If you do not have a good training set containing a diverse range of representative questions that will be asked by your users, then you can’t expect the resulting performance to be good.
In fact you can probably expect it to be worse because you are inadvertently trashing the underlying power of the language model.
In Helix, for example, we’ve worked hard on our ability to generate decent QA pairs with some success. But I have no doubt that there remains an open challenge for easily generating QA pairs for question answering use cases.
RAG is Better With Less Popular Topics
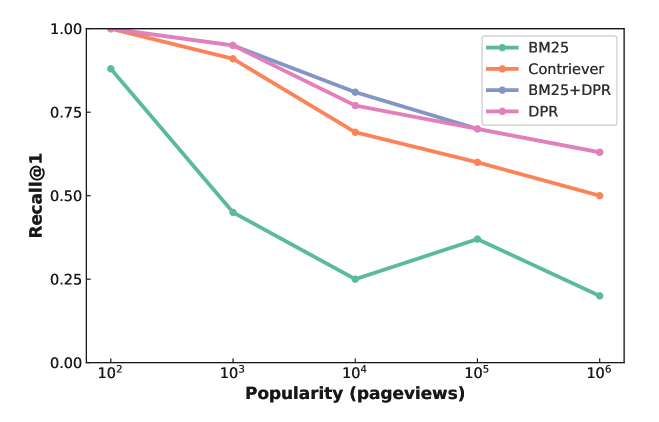
The second finding is that research suggests that rag works better with less popular topics.
This is a plot of comparing various RAG methods against questions that were generated for topics with varying popularity
The literature suggests that this is because more popular topics tend to have more noisy retrievals.
RAG+FT Works Better On Small Models

The third finding is that RAG plus fine-tuning works better on small models.
For larger models, much of the knowledge has already been learnt. So further fine tuning or rag adds little to the results.
But for small models, rag and fine-tuning both really help.
You Can FT On Time Series Data WTF

This is slightly out of scope, But it was so amazing that I couldn’t help but include it.
Finding 4 is that you can fine-tune on time-series data. In this paper, the authors removed the tokeniser and the embedding steps from the input in the output, and instead passed in a fixed context of numerical data to predict the output time-series.
Prompts matter

I included this because it’s crucial that you remember that the prompt is still really important.
In this paper they performed an experiment to compare different specificities of prompt. From really concise and simple really long-winded and precise.
They found it somewhere in the middle, somewhere around comprehensive instructions provided as guidelines excluding examples was the sweet spot.
When you look at these numbers comparatively, you can see that the effect is similar to that of fine-tuning. In other words, you can trash performance gains made through fine-tuning with a bad prompt.
Final Thoughts
And there we have it. A whistle-stop tour of RAG vs. fine-tuning. I hope you leave with a better appreciation of the nuances.
In general, RAG is probably more effective at incorporating external knowledge, but there are still good arguments to use fine-tuning. As always, it comes down to your specific use case.
If you’re interested in topics like these, then please sign up to our newsletter. You can also find our future events on our events page and lots more interesting information on our website.
If you have any other questions, then please feel free to email me at phil@winder.ai. And of course we have lots more interesting information