Part 1: Introduction to Large Language Models and ChatGPT
by Natalia Kuzminykh , Associate Data Science Content Editor
The launch of ChatGPT by OpenAI has attracted a lot of interest from people around the world, sparking curiosity not only about artificial intelligence in general but also about the underlying technology that powers this AI chatbot. While fancy terms like Large Language Models (LLMs) and Generative Models may sound complex, at their core, they’re really about helping computers understand and generate human-like text in almost any language (including programming languages).
Think of AI instruments like OpenAI’s ChatGPT or Google’s Bard as helpful assistants. They can make sense of long email conversations, help you write a better CV, and even come up with creative ideas for business campaigns. These tools are built on the Generative Pre-trained Transformer (GPT) language model: it takes in words, predicts what comes next based upon what it has seen in the past, and keeps going until it has a full message.
While many of us use these AI tools every day, it’s not always clear how they actually work. How are these language models built? How do they learn to understand words and make sense of them? How do we make sure they’re working properly and getting better over time?
In this series of articles, we’re going to address these questions by delving into the fundamentals of these models. We’ll take you on a journey through the entire life cycle of creating customized AI applications using ChatGPT-like models – from initial development to the stage of detailed training, thoughtful deployment, and continuous monitoring.
Large Language Models Anatomy
So, what truly lies behind LLMs? While a basic language model can digest text and predict sequences of words, the true game-changer with larger models is their capacity to learn from vast collections of unstructured or unlabeled data. These advanced models are based on a deep learning methodology that allows them to autonomously recognize and model complex patterns in data.
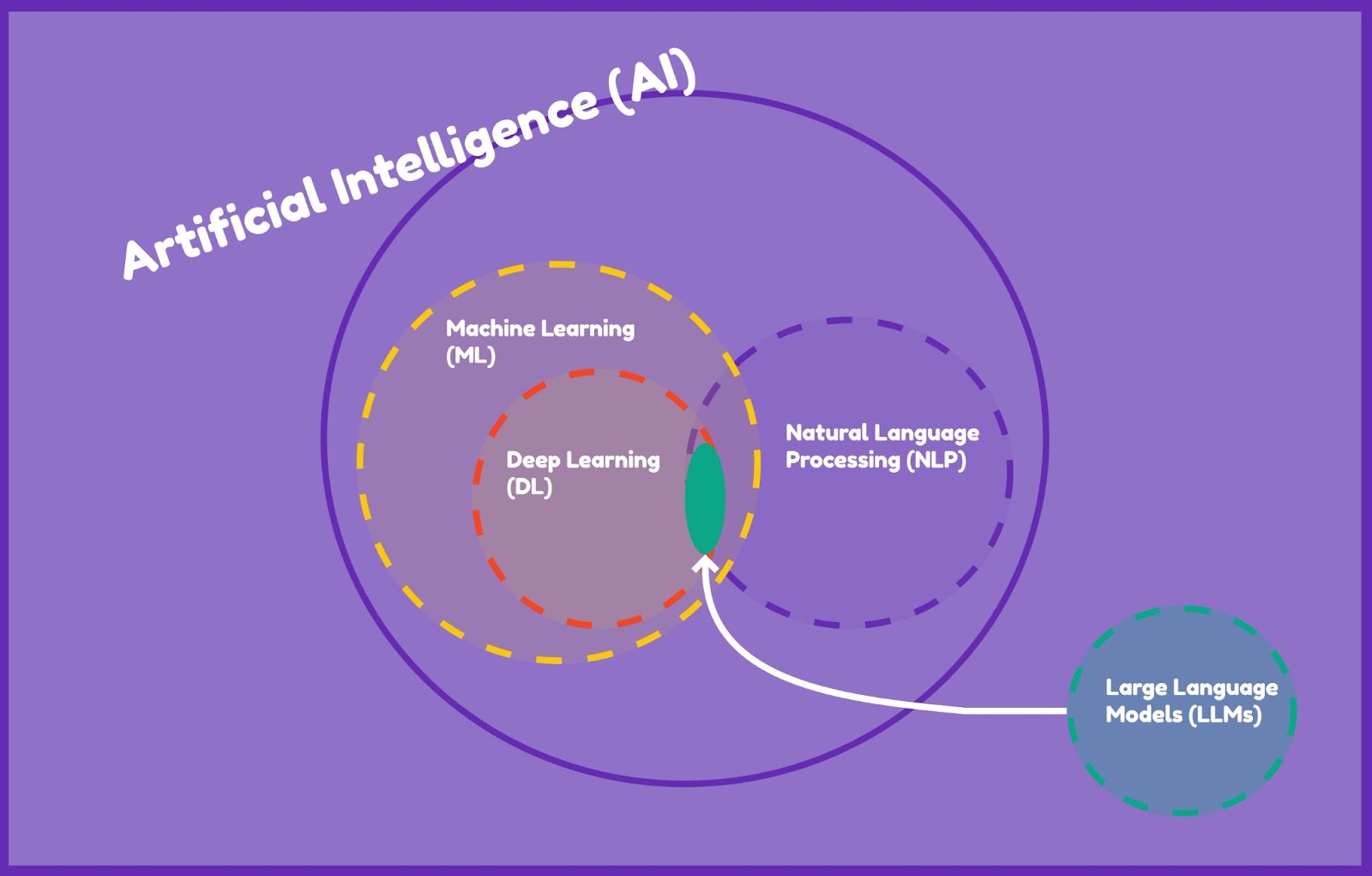
What’s even more fascinating is that these deep learning algorithms draw inspiration from our very own brain’s ability to learn from experiences. Typically, they’re constructed using artificial neural networks, which were inspired by the structure of our brain. Imagine a digital brain with billions of neurons working tirelessly to make sense of the data – that’s what these models essentially are!
It’s also important to highlight that underneath the hood of the LLMs lies a specific neural network pattern known as a transformer architecture. In simple terms, it can be represented as a two-part device with an encoder and a decoder, where the encoder processes the input text, while the decoder forms the output text.
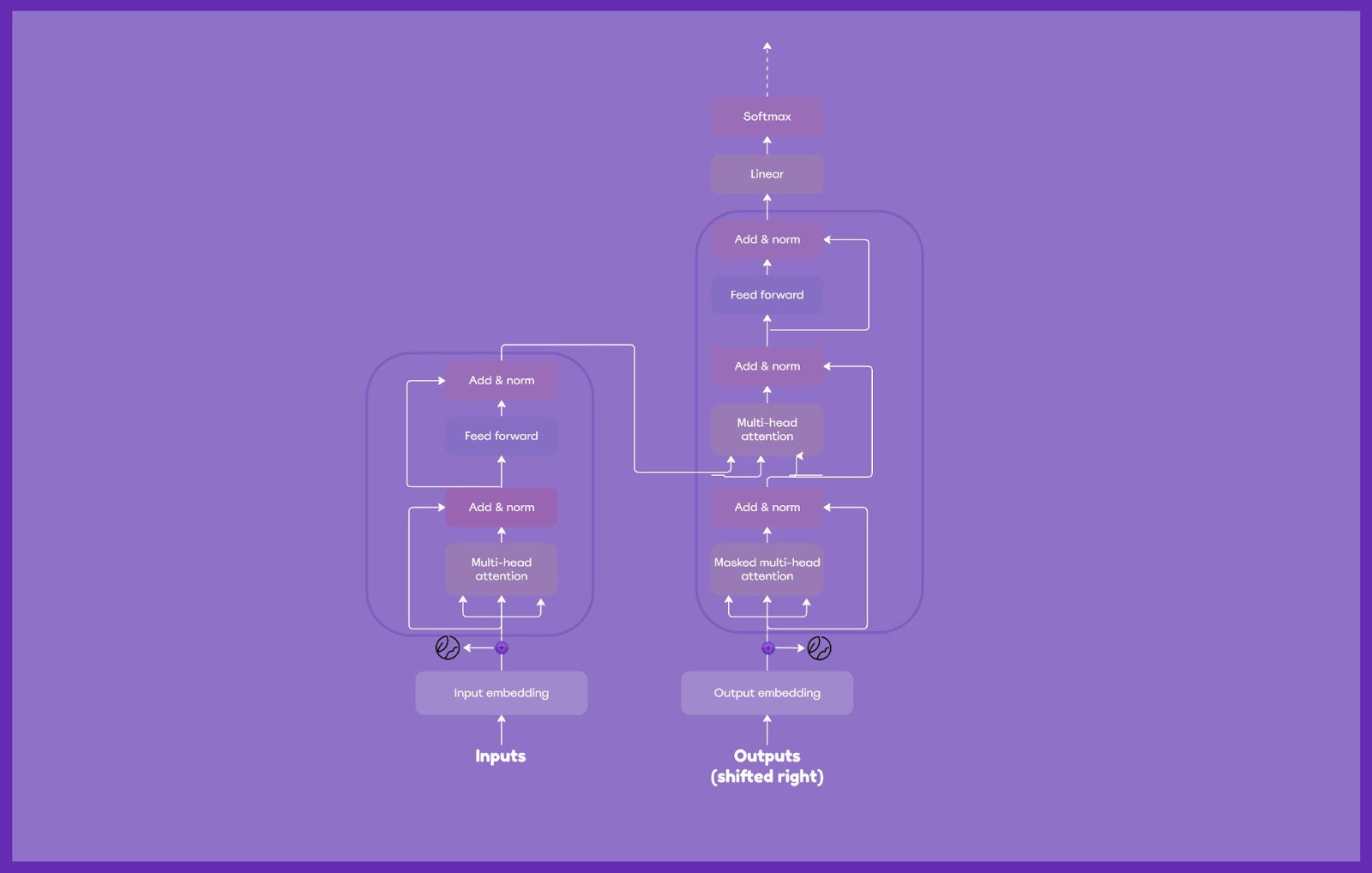
However, they don’t work alone. Both of them incorporate a multi-head self-attention mechanism that allows the model to assign different levels of importance to different segments of the text based on their context. Thus, this mechanism gives ChatGPT the remarkable ability to accurately interpret meanings and contexts within sentences.
Take the sentence “Apple is a tech company,” for instance. Here, the chatbot can understand that Apple is a tech giant, not a juicy fruit. In addition, the encoder uses a masked language modeling strategy to disentangle the connection between words, resulting in responses that aren’t only coherent but also engaging.
How does ChatGPT work?
Now, let’s focus on the self-attention mechanism, which is essentially the driving force behind models like ChatGPT. Generally, this mechanism converts text fragments, or tokens, into vectors that represent their relevance in the input sequence. Let’s break this process down into steps:
- First of all, the AI model forms three lists of numbers (vectors) for each word (a token): query, key, and value.
- Next, it measures the similarity between the query vector and the key vector of every other token, like comparing the relevance of two words in a sentence.
- It then generates normalized weights using a softmax function, which helps in understanding the relative importance of words.
- Finally, it forms a final vector, which encapsulates the token’s importance within the sequence, by multiplying the weights with the value vectors of each token.
The multi-head attention mechanism is an enhanced version of self-attention that permits the execution of the aforementioned steps in parallel, instead of implementing them sequentially with a new projection of the query, key, and value vectors every time. By expanding self-attention in this manner, the model is capable of grasping sub-meanings and more complex relationships within the input data.
Reinforcement Learning from Human Feedback (RLHF)
The release of the ChatGPT model marks a transformative moment in the AI landscape where normal people can interact with a model in a highly intuitive way. But also ChatGPT popularized a pioneering approach that Winder.AI have used for a while: reinforcement learning. ChatGPT integrates human feedback into the training procedure to train the model more effectively reflect user objectives using a technique known as reinforcement learning from human feedback (RLHF).
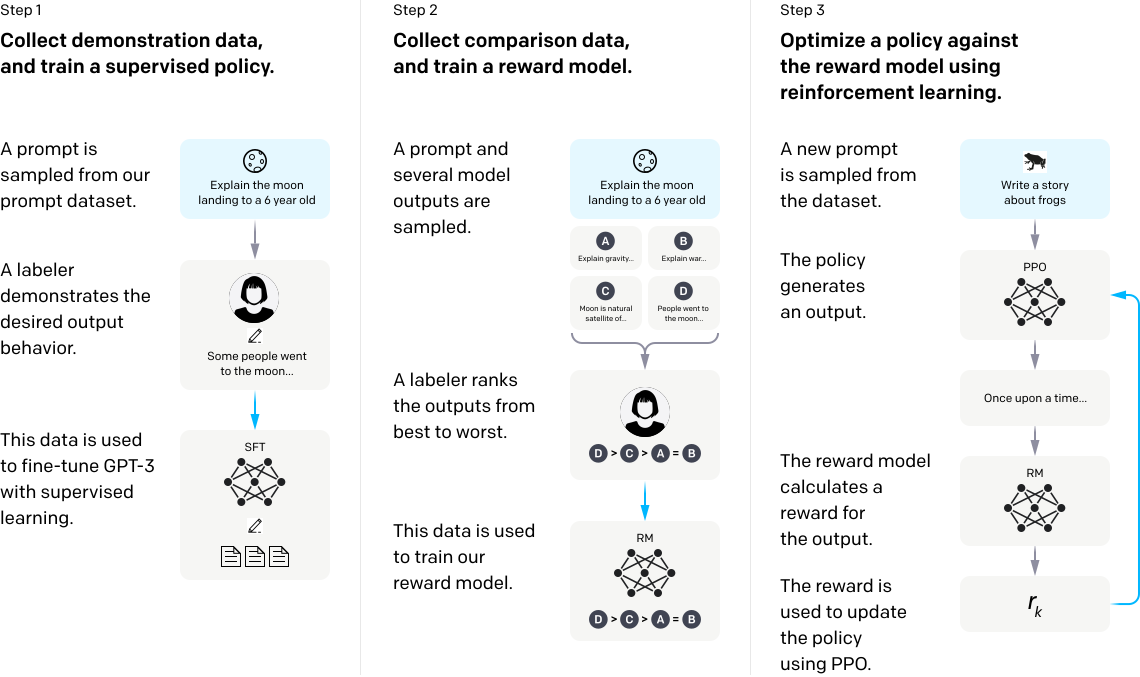
Starting with supervised learning from human examples, the initial phase involved presenting the pre-trained GPT with an annotated set of prompt and response pairs, produced by human reviewers. The aim was to allow the chatbot model to extract the appropriate behavior from these examples, resulting in a supervised fine-tuned model.
Next, a reward model was trained to assess responses from the generative model. The SFT model was utilized to produce a variety of responses to each prompt, which were then rated by human annotators based on quality, engagement, informativeness, safety, coherence, and relevance. This vital data was then fed back into the reward model, enabling it to learn human response preferences through supervised learning.
In the third phase, the reward model was implemented to refine the policy of the SFT model through reinforcement learning. Thus, for every response generated, the reward model would have assigned a value, reflecting human preference. This reward was subsequently used to optimize the generative model by nudging its weights to produce higher rewards.
So, if the generative model produced a response that the reward model predicted would appeal to humans, it would receive a positive reward, encouraging the generation of similar responses in the future, and vice versa.
This innovative training provided ChatGPT with the ability to respond to follow-up questions and acknowledge errors, making it a more interactive and engaging conversational partner.
Applications of Large Language Models
As mentioned previously, LLMs are fundamentally transforming the way we interact with language and data, with applications spanning various domains.

One significant area of change is search functionality, where LLMs are making searches more efficient and accurate. Unlike traditional search engines, that used keywords and knowledge graphs, these advanced models simply understand language better. They work much better with the growing trend of long-form searches and conversational cues that users use to find information. “Chatting” could even become a more intuitive search mechanism, whereby users refine results by clarifying the request based upon interim results.
LLMs also provide a robust platform for content generation and editing. They’re extensively applied to enhance productivity and automate processes that otherwise would need human intervention. Moreover, they prove beneficial in diverse scenarios: making chat-bots conversational, creating social media content, generating text feeds for text-to-speech systems, and writing stories for specific audiences.
The capabilities of pulling out important information from large amounts of unstructured data, like social media posts and customer reviews also distinguishes LLMs from traditional approaches. This kind of “structurizing” of data can give useful insights into how customers behave and what they like. Other conventional uses include text summarization, data clustering, and classification, making them handy tools for journalism, research, and data analysis.
Open Source Models
However, OpenAI isn’t the only player in the marker and the emergence of open source AI models have started a new period of open, available, and fair AI research. Let’s see some of the most outstanding examples:
- One standout example is the LLaMA model, which was introduced by Meta on February 24, 2023. LLaMA was made to be more flexible and responsible than its predecessors, offering a more robust framework. The model comes in several versions, with different parameters ranging from 7B to 65B. The release of LLaMA was a big step towards making AI development more democratic, as it gave researchers easier access to an advanced and responsible AI model.
- Another key player is the OpenAssistiant model. Released on March 8, 2023, as part of the LAION-AI project, the OpenAssistant model offers a comprehensive, chat-based LLM that’s accessible to everyone. Thanks to extensive training on an array of text and code, OpenAssistant can accomplish a wide variety of tasks, ranging from question-answering to generating text, translating languages, and even creating unique content.
- Also, Stanford University’s Alpaca, launched on March 13, 2023, is a compact instruction-following model, trained on a dataset of 52,000 instruction-following demonstrations. This model, based on Meta’s LLaMa model with 7B parameters, is designed to excel at a wide variety of instruction-following tasks, offering an affordable and reproducible solution. Despite similar performance levels, Alpaca is significantly more cost-effective to produce, costing less than $600, compared to OpenAI’s text-davinci-003 model, which was reported to cost approximately $5 million.
- On the conversational AI front, the Vicuna chatbot emerged as a compelling product of a collaboration between UC Berkeley, CMU, Stanford, and UC San Diego. Released in April 2023, Vicuna was trained on conversations from users and data from ShareGPT, and fine-tuned using the LLaMa model. As an auto-regressive LM based on transformer architecture, Vicuna delivers engaging and natural conversation capabilities. With 13B parameters, it not only produces more detailed and structured responses than Alpaca but also competes closely with ChatGPT in terms of conversation quality.
Conclusion
In light of our discussion, we see that both commercial LLMs like ChatGPT and open source LLMs like LLaMa are transforming our digital interactions. Through deep learning and reinforcement learning, these models are set to improve various areas of our daily lives, from search functionality and content generation to comprehensive data analysis.
Nonetheless, when building AI applications, as always, we must prioritize high-quality data, robustness, safety, and fairness, as substandard or biased solutions can lead to inaccurate and flawed model outcomes. It’s also crucial to be aware of potential pitfalls, such as content biases and hallucinations, particularly within ChatGPT-like frameworks.
In the forthcoming articles, we’ll explore not only a seamless integration of OpenAI’s models into your code, but also how to build a personalized LLM based on your data.