Google Releases AI Platform with help from Winder.AI
by Dr. Phil Winder , CEO
At their Cloud’s Next 19 conference, Google has announced the launch of an expanded AI platform. For a number of years Google has been expanding it’s portfolio to compete with AI products from Azure and AWS. But this is the first time that the platform can be considered “end-to-end”.
The AI platform consists of a range of products, each tailored to their own task. Some are now very mature, BigQuery, for example, has been around since 2010. But the two big additions are the tight integration of the managed Kubeflow service and, what we helped develop, the AI Hub.
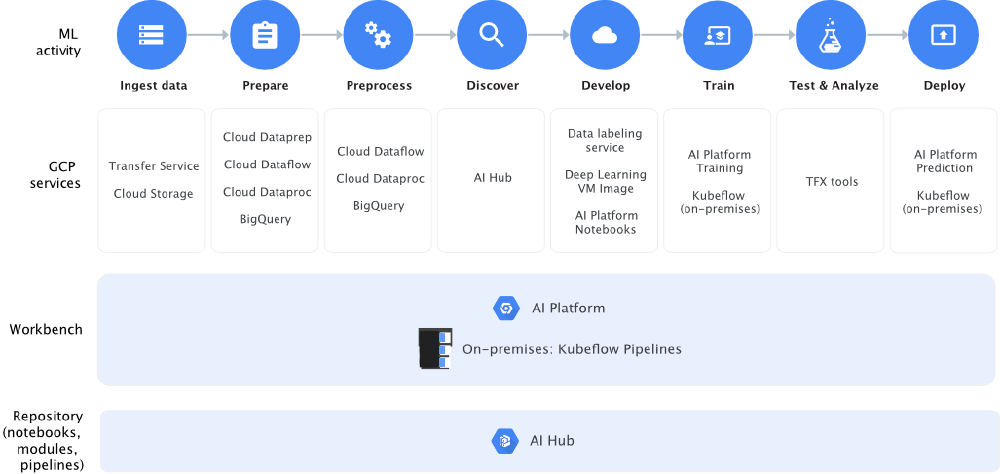
Kubeflow and Kubeflow Pipelines
Kubeflow is gaining a lot of traction, because up to now developing Data Science pipelines were always a custom affair. For each project you would begin with a basic pipeline in Python, split each phase out into Docker containers then attempt to hook them together with some complicated Docker Compose or Kubernetes setup.
Thankfully I can now talk about this in the past tense. Projects like Pachyderm are helping us to control dataflow. Kubeflow attempts to abstract out the development, training and serving of models. It provides these abstractions so you can perform these tasks in the same way every time. This is great news for companies that are developing internal Data Science platforms, because it standardises how Data Scientists develop. And best of all, it’s all Kubernetes-native.
Kubeflow pipelines is a companion project that provides a scheduling runtime for Data Science jobs. In other words, it’s a distributed pipelining tool. This is in direct competition with Pachyderm and at the moment Pachyderm has more features. But the tight integration with Kubeflow is a plus. Indeed, right now my clients are using both of these products in tandem.
AI Hub
In another strategy that is at odds with its competitors, Google is releasing a library of general purpose AI components. They comprise of a range of task specific pipelines, hosted Services and general out-of-the-box algorithms. I find this interesting, because it really does democratise Data Science. Rather than hoarding algorithms, they are promoting sharing and reuse.
Winder.AI helped develop some of the Text components (NLP) in a project that used the BERT word-level embedding for classification purposes.
Conclusions
With Kubernetes, Google is dominating cluster computing both on-premise (in-house platforms) and in the cloud. With the beauty of being able to migrate from one to the other very easily.
Google’s AI platform is aiming to do the same thing. They release their components under an open-source model to allow people to migrate from minikube to on-premise into the cloud. And I don’t begrudge this, I think it’s a win-win for Developers and for Google. We get better open-source tooling and they get people using their services.
If you need any help developing Data Science projects on Google’s AI platform or on-premise, please do get in touch.