Databricks vs Pachyderm - A Data Engineering Comparison
by Enrico Rotundo , Associate Data Scientist
Winder.AI has conducted a study comparing the differences between Pachyderm and Databricks. Both vendors are prominent in the data and machine learning (ML) industries. But they offer different products targeting different use cases. Modern, production-ready requirements present major challenges where data is evolving, unstructured, and big. This white paper investigates the strengths and weaknesses in their respective propositions and how they deal with these challenges.
Disclosure: This work was partially funded by Pachyderm, Inc.
What is Pachyderm?
Pachyderm provides the data foundation that allows data science teams to automate and scale their machine learning lifecycle while guaranteeing reproducibility. Data science teams can use Pachyderm to automate parts of the ML lifecycle using data versioning, pipelines, and lineage. Pachyderm offers an open-source community edition and a user-deployed enterprise edition. The enterprise offering includes role-based access control (RBAC), JupyterHub integration, and cloud and on-prem deployability. Pachyderm’s data-driven automation, petabyte scalability, and end-to-end reproducibility enable companies to go to market faster, minimize data processing and storage costs, and fulfil rigorous data governance needs.
Pachyderm’s core proposition is a data layer with built-in version control and lineage. But Pachyderm’s pipelines are also versioned. This allows you to not only orchestrate ML and data engineering pipelines but track them too. You can encode arbitrary directed acyclic graphs (DAG) by combining pipelines. And you can track data flows and executions back to their source.
Pachyderm’s technology is written in GO and usually deployed on Kubernetes. Pachyderm can instantiate your pipeline containers inside the same environment. Pachyderm supports all major cloud platforms by storing data in respective blob storage such as S3, Azure Blob Storage, Google Cloud Storage, etc.
Pachyderm offers an S3 interface so that data scientists can treat Pachyderm as a data lake, except that the full data versioning capabilities mitigate against accidents. This helps data scientists because they can continue to use the same tools they already know.
Pachyderm’s lineage features help both data scientists and the business maintain control over the data. Pachyderm records every data event, which includes the data source, the executing code, and the data sink. This metadata provides data lineage, enables reproducibility and helps an audit.
You can learn more on Pachyderm.com.
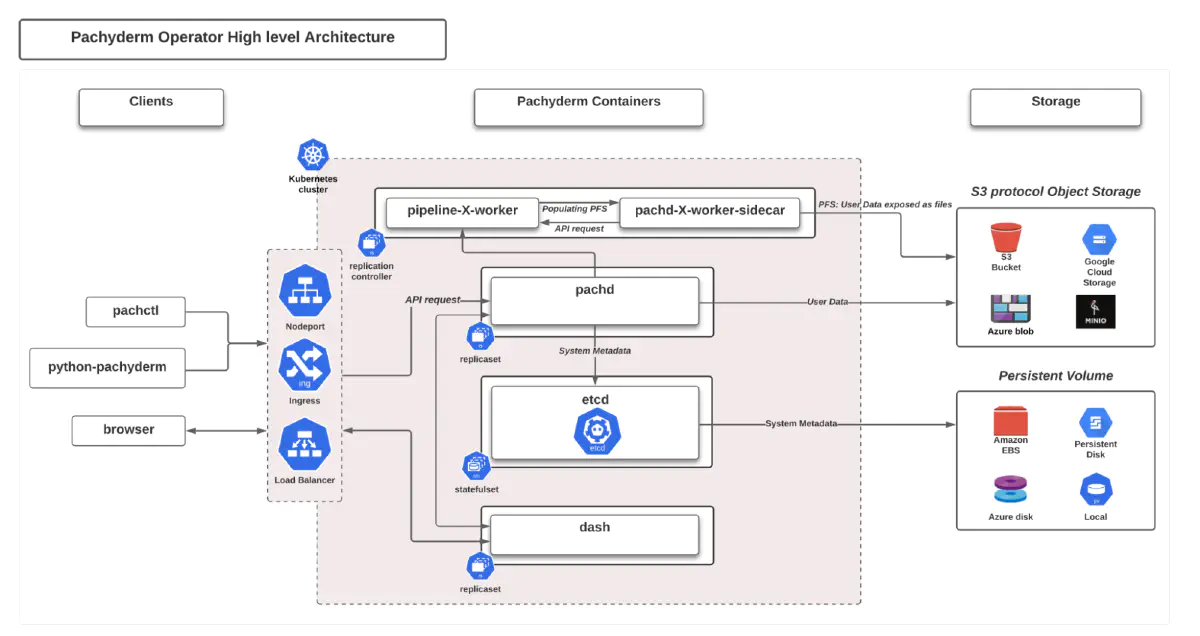
Image courtesy of Pachyderm, Inc.
What is Databricks?
Databricks is an Apache Spark-based analytics platform created by the founders of Apache Spark. Spark is a renowned all-around Scala/JVM-based data engineering framework capable of processing large volumes of data. Many cloud providers integrate Databricks into their offering, including AWS, GCP, and Azure. Databricks provides one-click configuration, streamlined workflows, and an interactive workspace. Databricks aims to ease collaboration between data scientists, pipeline engineers, and business analysts.
Spark’s goal was to outperform Hadoop by relying on in-memory computation while maintaining compatibility with the Hadoop Distributed File System (HDFS). As a result, it is particularly suited to distributing many small map-reduce style jobs across a cluster.
Over time, Databricks has extended its support to cater for modern needs. It expanded the Spark ecosystem with support for languages such as Python and R, and built several open-source libraries for ML (i.e., MLLib) and data lake capabilities (i.e., Delta Lake).
Although analytics workloads represent the core focus, Databricks has expanded into other areas. They enable the development of ML and data analysis projects, although they do this in a very Spark-centric way. Even so, Spark allows running powerful analytical algorithms on vast amounts of data, even with streaming data.
Thanks to a large user base, online resources on Spark have grown significantly, and the community generates many. For instance, the related topic on Stack Overflow has now crossed the +72k posted questions mark. Also, there’s a variety of events such as conferences, meetups, and webinars centered around Spark. Since 2013, Databricks have successfully hosted a yearly conference for sharing use cases and experiences with Spark.
In the era of big data, Databricks has emerged as a successful enterprise analytics system. Spark, although powerful, is complex to manage. Databricks has monetized Spark and its supporting ecosystem by providing a managed service, which is hosted by all the large cloud vendors.
Find more information on Databricks.com.
Image courtesy of Databricks, Inc.
Platform comparison
This paper aims to highlight the main differences between Pachyderm and Databricks. First, both are stable, well-supported systems for enterprise customers. Furthermore, you can deploy both platforms on major cloud providers and on-premise. Special praise goes to Pachyderm’s deployability on Kubernetes clusters. Although Spark can also be deployed on Kubernetes, it isn’t with the same ease.
Modern ML platforms should be able to perform well in scenarios where data evolves and comes in a variety of formats. Unstructured data, for example, is increasingly important. Evolving data implies the need for snapshotting different versions as well as inspecting lineage. Furthermore, production use cases often need to process new batches without re-running a job over the entire datasets. Thus it’s important to support incremental processing as well. Last but not least, systems should provide an amazing developer experience. Here’s a summary table of the comparison.
| Pachyderm | Databricks | |
| Structured and Unstructured Data | Both fully supported | Developed primarily for use with structured data |
| Versioning & Lineage | Built-in, hard lineage, long-term | Optional, metadata lineage, very short-lived |
| Incremental processing | Built-in | With caveats |
| Developer Experience | Language agnostic, cloud-native heavy | Scala/Java core with Python/R wrappers, requires expertise |
Intended Use Cases
It is important to note the use cases that each solution has in mind. Databricks is aimed towards the analytics market. Pachyderm is aimed at the data and data processing market. These are quite different and you might argue that this is an apples/oranges comparison. And you’d be right.
Pachyderm
Pachyderm is aimed at scalable containerized machine learning workloads which require strong lineage guarantees. But Pachyderm previously introduced streaming support in 1.9 via spouts. This allows you to ingest streaming data from message buses like Kafka and RabbitMQ, whilst retaining strong lineage.
If you want flexibility and provenance, Pachyderm is a great choice.
Databricks
Databricks and Spark was designed for analytics use cases. That’s why they’ve invested in so many SQL technologies. But don’t expect to be able to work with unstructured data or machine learning. For example, Databricks supports the use of Tensorflow/Pytorch via Horovod, a completely separate cluster manager, with nothing to do with Spark. MLLib, Spark’s machine learning library, is not well suited to modern batch ML needs. It is useful in streaming applications, however.
If you need a solution to handle complex analytics needs, Databricks is a great choice.
Structured and Unstructured data
Enterprises rely on unstructured data for regulatory, analytic, and decision-making purposes. Unstructured data also drives the innovation of analytics, machine learning, reinforcement learning, and business intelligence. According to ITC, the volume of unstructured data is expected to grow to 175 billion terabytes by 2025. So it is important for businesses with artificial intelligence products to pair the right tooling to their data strategy.
Pachyderm
Pachyderm can handle unstructured data at scale. It supports video, audio, imagery, unstructured text, or complex domain specific data types. It achieves this through a hybrid approach based on object storage, a copy-on-write style file system used for snapshotting, and a Git style database for indexing.
Pachyderm leverages the scalability of a cloud’s blob storage to provide native performance to any application.
Within a pipeline, Pachyderm exposes data repositories as local directories. This makes it easier to bootstrap a transformation pipeline on unstructured data because user code can access files locally. Also, this approach decreases dependencies to external libraries for fetching remote data. Thus, it streamlines data consumption without using any specific API or SDK.
Pachyderm can manage large dataset repositories comprising billions of files and many petabytes of data. Data deduplication, provided via incrementality, only stores the updated chunk, making it particularly suitable in scenarios with large amounts of evolving data.
Pachyderm also works for structured datasets via the same interfaces, but unstructured files are the biggest differentiator.
Databricks
Delta Lake is a storage layer added on top of the native cloud storage to provide versioning and uniformity. The tool reviews all incoming data and ensures that it matches the schema set up by the user. This helps to ensure that the data is reliable and correct.
Delta Lake is compatible with Apache Spark APIs. This allows it to support data lake metadata, among other things. Delta Lake can run on on-premises servers, in the cloud, or on devices such as laptops. It is compatible with batch or streaming data sources.
However, Databricks Delta Lake has been developed with structured data in mind. It provides the user with a tabular data structure to be used as a DataFrame. This suits all table-like datasets, but is a problem for unstructured data. It stores binary data as a table record, which causes a variety of management, scalability and versioning issues.
Using unstructured data in Delta Lake is rare and at the time of writing there is only one example publicly available.
One benefit of Databricks spark, in terms of data connectivity, is that it has a large list of out-of-the-box connectors. This makes the task of extracting data quite easy, as compared to having to write your own connectors.
Versioning & Lineage
Pachyderm
Pachyderm provides an automated and efficient way to keep track of all data changes thanks to its Git-like approach. It fosters effective collaboration through commits, branches, and rollbacks. This enables a complete audit trail for all data and artifacts across pipeline stages, including intermediate results with its file-based versioning.
Pachyderm saves changes as native objects in a chunked format, not pointers. This optimizes storage costs because it only stores new chunks that have changed. This philosophy also promotes “hard” lineage. You cannot alter the commit history because the versioning would become corrupted.
It snapshots changes into commits that are immutable and persistent. As in git, with Pachyderm, you can branch out a repository and design multi-faceted pipelines. Also like git, you can “time travel” through your commits to see previous data and runs. This is valuable in ML because it allows you to version control your experiment metadata like hyper-parameters alongside your data.
The screenshot below depicts the details of a commit. The commit’s unique hash is linked to the parent commit hash to provide provenance.
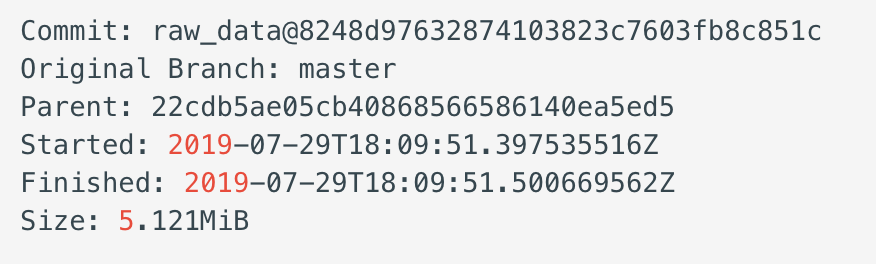
An example of Pachyderm’s commit information.
Databricks
Databricks enables version control by default when you use Delta Lake, although you can use Databricks Spark without it. Delta Lake tags every write operation with a timestamp and an incremental version number. You can use these tags to read from a previous point in time, as shown in the following snippet.
df = spark.read \
.format("delta") \
.option("timestampAsOf", "2022-02-01") \
.load("/path/to/my/table")
Delta Lake persists every change in a transaction log and the “describe history” command lists all versioned operations indicating their origin. This is a metadata approach to versioning, where pointers point to full rows in the persisted data, and provide “soft” lineage. For example, it is possible to forcibly alter the underlying data that the metadata is pointing to.

Example output from Delta Lake’s describe history command.
Delta Lake’s version history allows you to roll back to a previous version of your data table. This is ideal for undoing unwanted operations, but in contrast to Pachyderm, the scope of history in Databricks is rather limited in time.
While Delta Lake stores commit metadata in a separate JSON log file, the actual data is saved across partitions (in parquet files). The image below shows the internal structure of a Delta Table.

Delta Lake data storage format
As the table grows, the number of internal files grows. As the number of partitions increases, it takes longer for Delta Lake to parse these files. To maintain performance, Delta Lake regularly compacts commit metadata and by default removes access to commits older than 30 days. Thus, Delta Lake limits the history to 30 days into the past. It is possible to change this setting, but it will impact performance and is not recommended.
Also, note that old data parquet files must be garbage collected manually. By default, this removes all data older than seven days. To access 30 days of historical data after a manual garbage collection, you must increase the data retention period from 7 to 30 days.
Because of the lack of chunking (see the next section) this can lead to a large amount of duplicate data which not only increases the size of the partitions but also uses excessive storage space. Databricks recommend minimizing the data retention period for performance reasons.
These temporal limitations ultimately prevent Delta Lake from being used as a version control system for data. For true version control, commits and data should be persisted and accessible for as long as the project demands it.
Incremental Processing
Incremental processing is a functionality that allows you to only process new data, instead of re-processing the entire dataset. This approach enhances efficiency by eliminating the need to re-process unchanged data.
Pachyderm
In Pachyderm, you build a multi-step data ingestion pipeline as a DAG via configuration. You will specify various settings such as the user code (or container) and the input data sources. Pachyderm manages the computation of data in adatum.
A datum is a Pachyderm abstraction that enables pipeline processing optimization. It exists only as a pipeline processing property and describes the data processed in each instantiation of a job. By controlling the size of a datum, Pachyderm only needs to process data that has changed.
For example, if you imagine each datum being a file, then Pachyderm will treat each file as an independent processing job. This aids scalability and also allows Pachyderm to generate a new output by only re-processing files that have changed.
Thanks to the datum concept, Pachyderm can discern and process only the latest additions. Incremental processing minimizes computing time and allows for better resource utilization.
Databricks
A Spark batch job operates on immutable in-memory data structures (e.g., RDD, DataFrame). This means that Delta Lake must load partitions into memory to perform a task. A user can control the size of a partition to a degree, by carefully managing data, but out of memory exceptions are common.
Users can also implement incrementally in batch processes with carefully crafted queries. For example, if the table has timestamps, you could operate only on records that have a new timestamp. But this is not provided out of the box, it is up to the user to implement this.
Spark streaming provides checkpoints to point to the location where processing should resume if a job stops. It also provides triggers to start small jobs based upon individual messages.
But neither of these are incremental. Both checkpoints and triggers don’t deduplicate work that has already been completed. And as a user, you can’t control the level at which incrementally happens. For example, if one character has changed within a binary blob, the whole record must be recomputed.
The Delta Lake approach requires more complex data and software engineering to identify and take advantage of incremental data. Users need to define specific queries to only process incremental data, and there’s no tracking whether a particular subset of incremental data has been processed.
Language support
The ability to run any language or code on your MLOps platform enhances flexibility. It enables your team to get to production-level deliverables faster by leveraging the best framework for the job. It also helps when your business is attempting to standardize.
Pachyderm
Pachyderm is natively language-agnostic. It executes any containerized program. As a result, you can leverage whatever tools are best suited for your use case, even Spark!
Databricks
Although the official Spark libraries support Python and R, they are only wrappers around the underlying Scala/Java core. Using wrappers decreases the developer experience because it binds the user to Java ways of working. And it only implements a subset of the Scala API.
Troubleshooting errors presents an extra layer of difficulty. Most errors you may encounter while using PySpark, the popular Python library for Spark, will display a stack trace containing both Python and Java exceptions (find someexamples here). This places another burden on the ML practitioner to understand the Java API.
Developer Experience
The developer experience is an important feature because it defines the upper limit of productivity. If common ML or MLOps tasks are difficult to perform, this burdens the developer with extra work.
Pachyderm
Pachyderm’s recommended deployment target is Kubernetes, although you can run it as a binary. This means you can deploy to any cloud or on-premises. Enterprise versions come with a UI and hosted notebooks to improve usability.
Databricks
Apache Spark comes with a set of Web UI/User Interfaces for Jobs, Stages, Tasks, Storage, Environment, Executors, andSQL. This allows for rudimentary monitoring of the status of your application and cluster.
Interaction with the Spark cluster is via the Spark CLI which is useful for rapid development. This also makes it nearly impossible to create immutable jobs, unless you force users to abandon local CLI usage. It also makes dependency management difficult, especially when using Python, because you can’t build a well-known artifact.
You can deploy Spark in stand-alone mode, which is useful for development, or with a cluster manager. Spark was commonly deployed with Mesos or YARN, but these are out of date and were hard to operate — so much so that it drove most users to the cloud-managed Databricks suite. Spark also offers aKubernetes deployment mode, but its implementation is not straightforward.
Integration With Other Tools
Pachyderm
Pachyderm’s arbitrary containers allow you to develop code that can interact with any external ML tool. You can even store artifacts in Pachyderm and refer to them from an external tool.
In the past, Winder.AI have demonstrated integrating Pachyderm with Seldon. Click here to find out more about that case study.
We will demonstrated how you can integrate MLFlow with Pachyderm, using Pachyderm as the backing store, to enhance lineage. We even have an example of running Spark inside Pachyderm!
Pachyderm also maintains a collection ofexample integrations in their repository and you can find many more via a search engine.
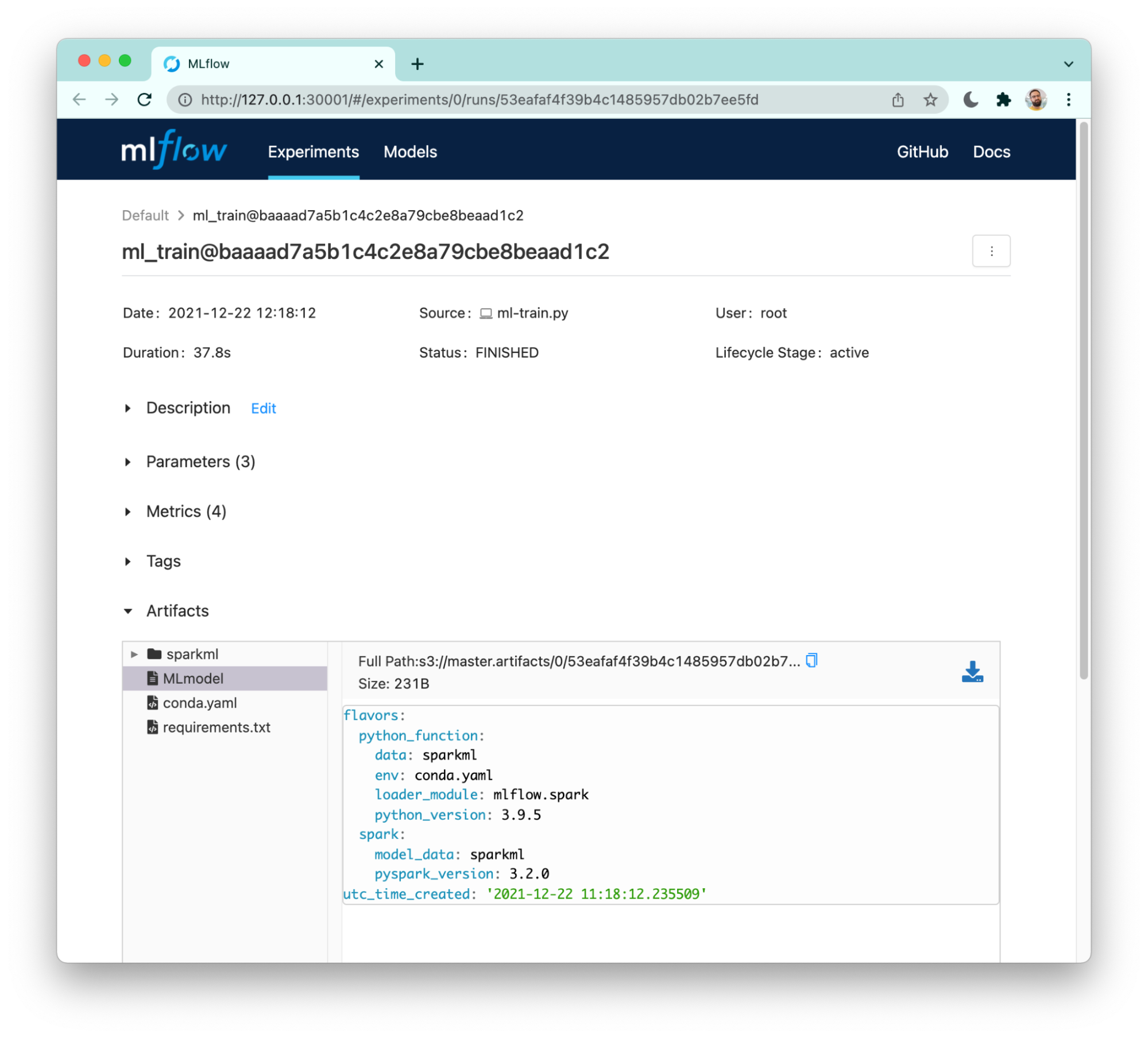
Pachyderm integration with MLFlow.
Databricks
MLFlow is an open-source metadata store with adedicated API for logging and loading models. By default, it is delivered as a library, but we curateour own container builds. Databricks offers a managed MLFlow instance in their cloud platform, making it their selected tool for tracking experiments and managing ML artifacts.
However, MLflow and Spark alone do not provide lineage. For example, you can delete or modify artifacts without MLFlow knowing about them. This requires the user to establish and use sensible working practices.
There’s also no direct link to the data or code, which means that you have to manage reproducibility on your own.
Alone, MLFlow is more suitable for a series of experiments by a single data scientist or a small team. Larger teams will want to focus on reproducibility and lineage features.
Despite these drawbacks, MLFlow is a very useful tool. It has become the defacto open-source ML metadata management solution and we use it extensively, even with Pachyderm!
Spark and the rest of the Databricks suite can be integrated with other tooling if you’re comfortable adding this to your Spark code. You can also interface with MLFlow via its API. But you can’t run arbitrary code like you can on Pachyderm, so it’s not quite as flexible.
Specification of the Processing Graph
When engineers develop their data pipeline architecture the specify the processing tasks as a directed acyclic graph (DAG). Splitting workloads into small, sharded tasks makes it easier to horizontally scale the job. But how do you do that in Pachyderm and Databricks?
Pachyderm
In Pachyderm, you have full control over the DAG. You are free to decide how data is sharded and what code you run. It is simple and obvious — two great qualities.
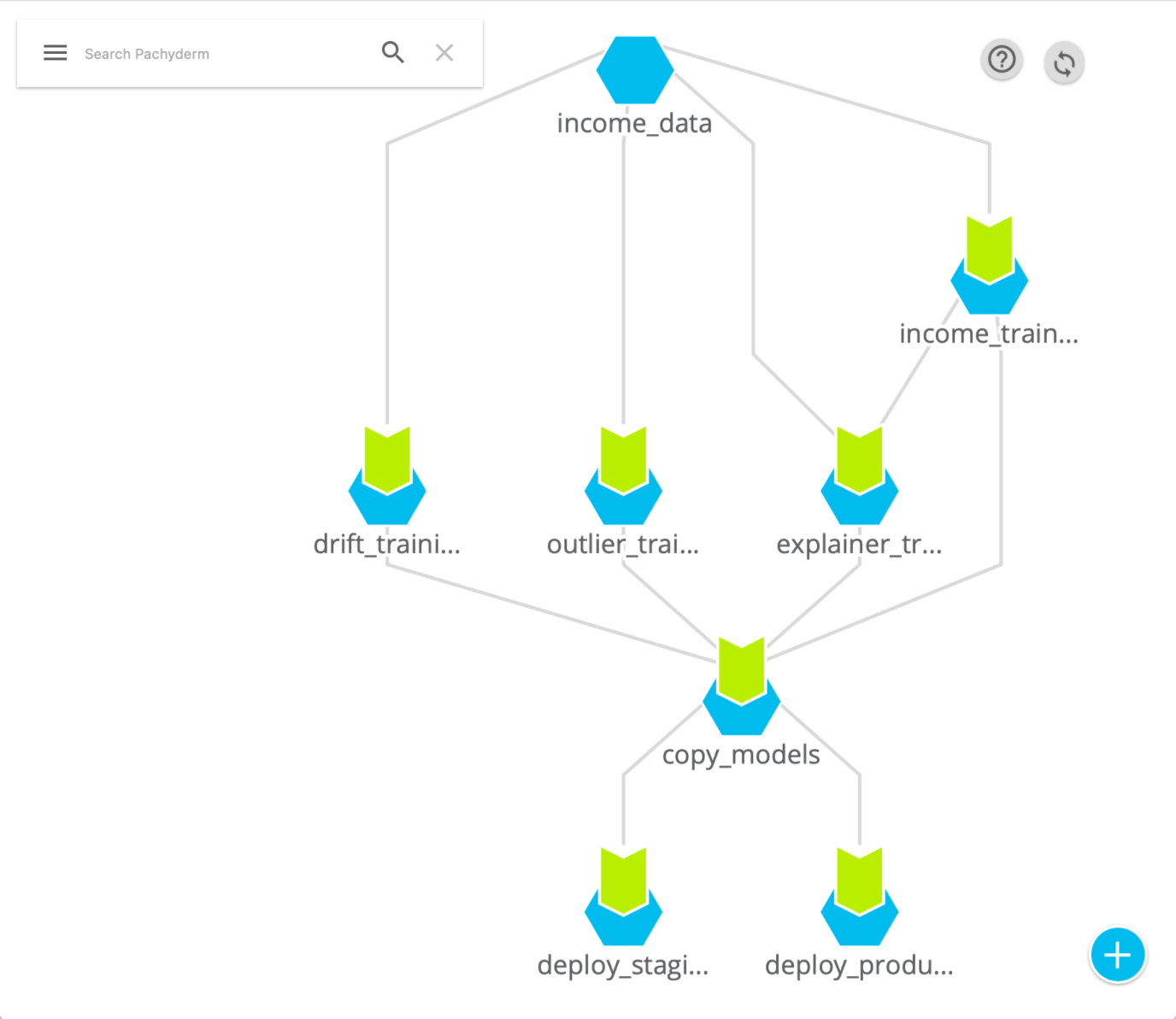
An example Pachyderm DAG from our Pachyderm-Seldon integration case study.
Databricks
Spark forms the DAG via the code that you write. So although you have control, it is hard to control, because the compiler decides what the DAG looks like. And when you’re using PySpark this process is even more obfuscated.
But this does enable the fundamental difference in Spark. Spark runs the DAG lazily. It waits until an output is requested and self-feeds that back through the DAG.
This is useful in analytics because it means it only runs the part of the DAG that has dependent jobs, thus optimizing utilization.
But it can add significant delays to data being processed. And it also means that you’ll still need a third-party scheduler to trigger jobs if they are batch. In Spark streaming, you can use Triggers.
But more importantly, this makes it really hard to control parallelization. If you have a really large job, it’s typically easier to buy a bigger machine than it is to try and alter the code to shard the data better. Memory management is the number one issue.
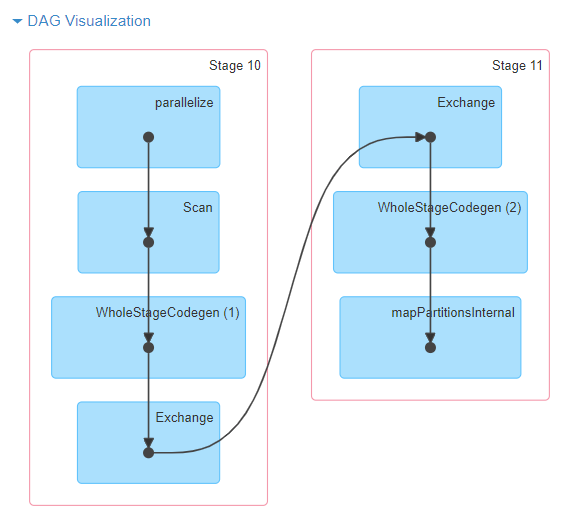
An example Spark DAG visualization.
Fundamental Differences in Philosophy
There are two fundamentally different philosophies here. In Pachyderm the data drives the computation. In Databricks, the output drives it. In Pachyderm you control the sharding. In Databricks, the compiler attempts to handle it.
If you have mainly SQL-like workloads, which are ripe for optimization, then I’d suggest that the compiler controlled DAG generation makes sense. But for ad-hoc ML workloads, we prefer control.
Other Features
Notebook Hosting
Both offerings now support Jupyter notebook hosting to make it easier to interact with the platform.
Pachyderm notebooks leverage a customized JupyterHub deployment running inside and authenticated against your Pachyderm cluster. As a result, Pachyderm enables its users to benefit from data versioning and lineage to enable reproducibility. At the same time, ML engineers can productionize those pipelines faster, efficiently, and securely.
Databricks also offers shared and interactive Databricks notebooks for real-time co-authoring, commenting, and automated versioning simplifies collaboration while providing control. In addition, its APIs and Job Scheduler enables data engineers to quickly automate complex pipelines, while business analysts can directly access results via interactive dashboards.
SQL Optimization
Databricks is Optimized for SQL workloads. Photon increases the parallel processing of data and instructions at the CPU level. Other Delta Engine components include an enhanced query optimizer and a caching layer. In addition, Photon can connect to any SQL data source.
Summary
Pachyderm and Databricks both offer a large set of features to streamline your data science projects and produce production-level high-quality deliverables. But both have their niches. Use the guide below to decide which is right for you.
Pachyderm may be the best choice if you:
- work with unstructured data
- value long-term, hard lineage
- prefer generic arbitrary processors in the form of containers
- prefer cloud-native solutions
- you have more general ML use cases
- want to use arbitrary external frameworks
Databricks may be the best choice if you:
- have analytics workloads and are working with structured data
- do a lot of your work via SQL
- you want a low management burden, via the managed services provided by GCP/AWS/Azure
- love Scala/Java