ChatGPT from Scratch: How to Train an Enterprise AI Assistant
by Dr. Phil Winder , CEO
This is a video of a presentation investigating how large language models are built and how to use them, inspired by our large language model consulting work. First presented at GOTO Copenhagen in 2023, the video investigates the history, the technology, and the use of large language models. The demo at the end is borderline cringe, but it’s a fun and demonstrates how you would fine-tune a language model on your proprietary data.
Presentation
Slides
Download SlidesAbstract
In today’s fast-paced business environment, the demand for intelligent enterprise assistants that can help optimize workflow, handle customer queries, and even automate tasks is at an all-time high. But how do you go about creating a powerful and reliable conversational agent like ChatGPT? This tutorial aims to answer exactly that question.
We invite developers, data scientists, and tech enthusiasts to a rapid tutorial on building Large Language Models (LLMs) tailored for enterprise applications. We will delve into the architecture, training methodologies, data pipeline construction, and optimization techniques required for creating a state-of-the-art enterprise assistant. Participants will gain experience with LLM with a comprehensive LLM walkthrough along with the foundational knowledge required to build, fine-tune, and deploy LLMs in an enterprise setting.
Key Takeaways:
- A Brief History of LLMs: Tracing the evolutionary journey of Large Language Models from their rudimentary forms to cutting-edge architectures like GPT-4, and understanding their impact on the field of Natural Language Processing (NLP).
- Understanding the core architecture and components of Large Language Models like ChatGPT.
- Techniques for curating and pre-processing domain-specific datasets that result in a highly specialized and efficient LLM.
- Strategies for efficient and cost-effective model training, from fine-tuning pre-trained models to training from scratch.
- Deployment considerations for LLMs, including the use of cloud-based services like AWS and Azure.
- Security and ethical considerations in deploying LLMs in a business environment, including data privacy and model interpretability.
By the end of the tutorial, attendees will have a working knowledge of LLMs and the confidence to prototype intelligent conversational agents for their organizations. Whether you are a novice exploring the world of NLP and machine learning or an experienced developer looking to upskill, this tutorial has something for everyone. Come join us as we demystify the intricacies of developing enterprise-grade LLMs!
Presentation Outline
Section 1: A Brief History of LLMs
LLMs are AI models that use supervised learning on vast text-based datasets and are refined by reinforcement learning through user feedback. The goal of LLMs is to predict the next word in a sentence, which allows them to generate human-like text.
The history of AI models designed for language dates back to the 1960s, with an early example being Eliza, a program that mimicked conversation by using a set of pre-scripted heuristics to ask questions.
A significant advancement came in 2013 with the introduction of word embeddings in the Word2Vec paper, allowing the conversion of text into numerical representations that can be manipulated mathematically.
Progress continued with improvements in machine learning models that treated text as sequences of tokens, which led to more accurate predictions of the next token in a sequence.
The development of Transformers, BERT, and the GPT series (GPT-1, GPT-2, GPT-3) brought advancements in how models understand and generate text, mainly through increased scale – larger datasets and model sizes.
The launch of the ChatGPT interface in late 2022 marked a point where LLMs became widely recognized, to the extent that Dr. Winder no longer had to explain what AI was to the layperson.

Section 2: Core Architecture and Components
Section 2 discusses the process of building large language models (LLMs) and provides insights into their architecture and the reinforcement learning used to refine them:
Training Large Language Models: LLMs begin with a vast text data corpus, which can be from the web or books. The model is trained in a supervised manner to predict the next word or token by giving it part of a sentence and asking it to continue. Incorrect predictions are used to adjust the model parameters to improve future performance.
Collecting Comparison Data: Human feedback is collected to rank outputs from the model. This step incorporates safety, ethics, and goals. A reward model is trained to predict human scoring of outputs.
Transformer Architecture: Introduced in 2017, this architecture has two main parts: input and output sides. The input side processes raw text into a higher-dimensional space, while the output side generates answers based on a given prompt. Subsequent improvements realized that only the output side was necessary for models like GPT, which focuses on text generation.
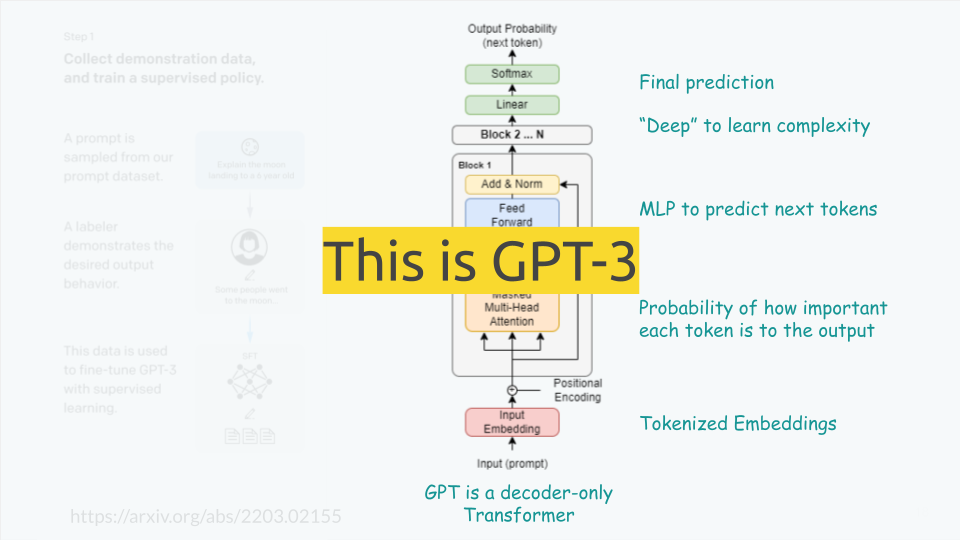
Tokenization and Embedding: Text is converted into tokens, typically using subword sequences, which are then transformed into a high-dimensional embedding space.
Multi-Headed Attention: The architecture uses multi-headed attention mechanisms to determine the importance of each token to the output, focusing on forwarding only the significant parts through the network.
Deep Learning Layers: The model incorporates many layers (deep learning) to add complexity and improve predictions, ending with a softmax layer to choose the most probable next token.
Reward Model Goals: The reward model serves three main purposes: alignment (making the model do what it’s intended to), safety (ensuring the output is safe), and quality control (maintaining the output quality).
Quality Control Risks: An example discusses how chat-generated content on the web could be re-ingested as training data, potentially causing a feedback loop that could deteriorate the quality of the model’s output.
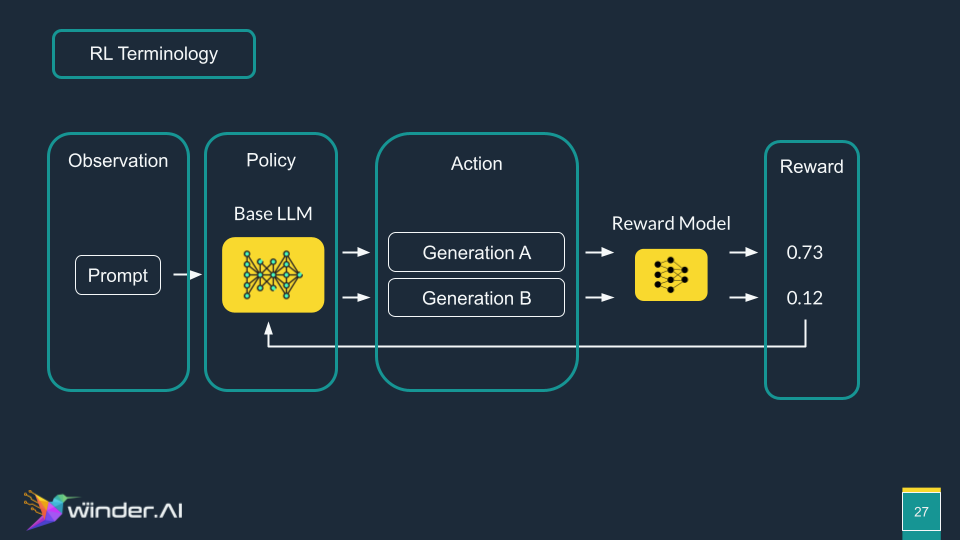
Reinforcement Learning Loop: This is an iterative process where the model generates options, the reward model evaluates them, and the feedback is used to refine the LLM. In reinforcement learning terms: the observation is the prompt, the policy is the base LLM, the actions are the outputs, the reward is provided by the reward model, and the environment includes the reward model affecting the policy.
Reinforcement Learning Book: Our book on reinforcement learning available at rl-book.com for those interested in a deeper dive into reinforcement learning.
Section 3: Data Preparation
Data is of critical importance in AI and machine learning, particularly in the context of large language models (LLMs). Here are the main points summarized:
Data Quality: The quality and quantity of data are fundamental for the superior performance of AI models, particularly in machine learning.
Massive Data vs. Proprietary Data: Large datasets generally lead to better-performing models than smaller, proprietary datasets. However, integrating proprietary data with pre-trained models can enhance domain-specific performance.
Curation Challenge: Curating data is a difficult and labour-intensive process. There is no one-size-fits-all approach to data cleaning, as highlighted by the “No Free Lunch” theorem, indicating the need for domain-specific data cleaning strategies.
Scepticism Towards Automated Data Cleaners: While automated data cleaning tools exist, they are not perfect. Domain expertise often plays a crucial role in effectively cleaning data.
The Falcon Model Case: This illustrates that improvements in LLMs can result from better data cleaning rather than changes in architectural design. Simple actions like deduplication and removal of irrelevant content can have significant impacts.
Human Insight in Data Cleaning: Domain experts can outperform current algorithms in data cleaning tasks, proving that human expertise is still highly valuable in the data preparation phase.
Tokenization and Domain-Specific Terms: The section also touches on tokenizers (referred to as “tokenizers” in the text) and their limitations in handling domain-specific vocabulary. Adjusting tokenizers for specific fields, like healthcare, may improve model performance.
Avoiding Over-Engineering: Be cautious not to overcomplicate solutions with advanced models when simpler ones, like logistic regression, may suffice.
Diversity of Training Data: Training data can come in many forms, from raw text to data formatted for supervised learning and reinforcement learning scenarios.
Overall, the section drives home the point that while large pre-trained models are powerful, the careful integration and cleaning of domain-specific data is key to achieving high performance in specialized tasks.
Section 4: Modelling and Training
This section investigates how to train a large language model. It becomes quickly apparent that it is infeasible to train a language model from scratch, as it requires a vast amount of data and computational power. Instead, we can use a pre-trained model and fine-tune it on our data.
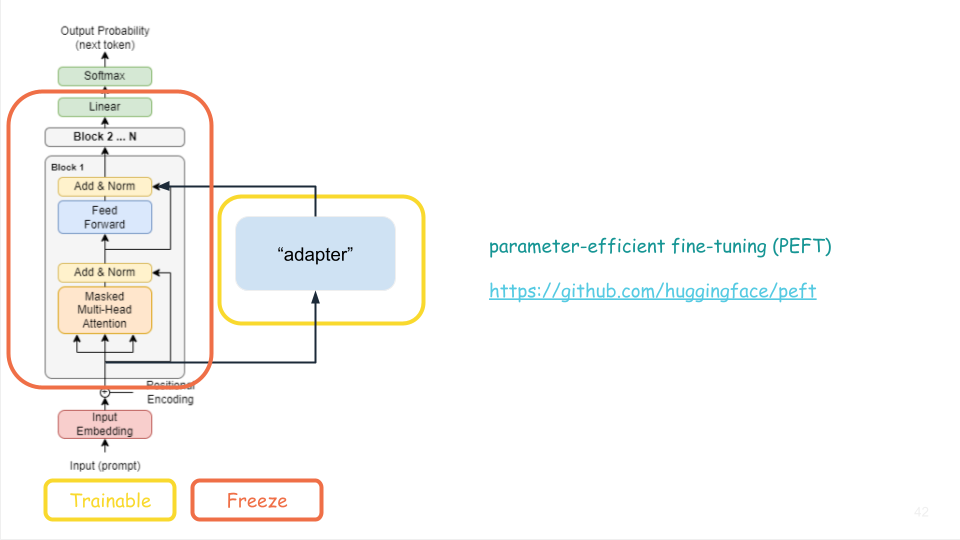
“Adapter” models, essentially a smaller, more manageable model that works alongside the foundation model, are introduced as a novel approach that can be trained on reasonable hardware in reasonable amounts of time.
Despite this innovation, the problem of managing billions of weights, each requiring memory storage, persists. Large, modern models are unable to fit inside a single commercial GPU.
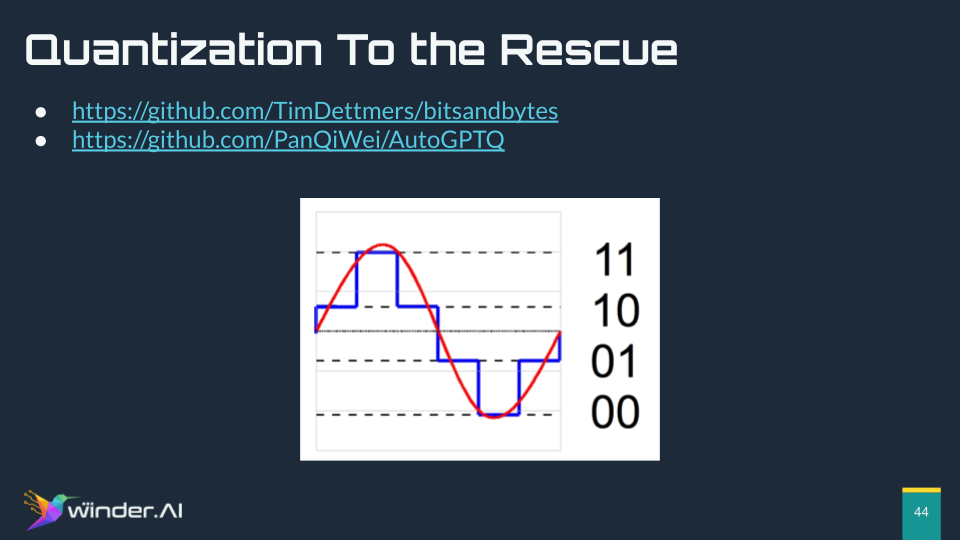
To counteract the memory issue, I turn to the concept of quantization – reducing the number of bits required to represent each weight without excessively compromising the model’s integrity. This technique enables the compression of model sizes, making them more manageable.
Lastly, I remind the reader that, despite the complexities of training and optimization, LLMs are already quite sophisticated even in their unaltered state. By simply manipulating the input prompts, one can achieve impressive functionality. To illustrate this point, I share an intriguing example of MrReindeer.com, which leverages prompts to write code that effectively runs on an LLM, transforming the model into a runtime environment for generative applications. This example not only showcases the potential of LLMs as educational tools but also underscores their versatility and power straight out of the box, offering an avenue for developers to create sophisticated applications without delving into the underlying complexity of the model itself.
Section 5 & 6: Deployment and Hardening
I explore the complex nature of adversarial attacks on large language models (LLMs) and the inherent challenges in safeguarding these systems. I drew attention to the reality that all models, including AI models, are susceptible to attacks if there is a determined effort. Specifically, I pointed out that adversarial attacks manipulate the prompt to make the model perform undesired or unintended actions. This can circumvent the protections set during the model’s reinforcement learning phase, as demonstrated on the website LLM attacks.org, which utilizes an adversarial suffix.
The discussion included parallels I’ve drawn from my prior experience in cybersecurity, notably the use of reinforcement learning to attack web application firewalls via adversarial SQL injection queries. This analogy highlights similar vulnerabilities between LLMs and SQL databases in how both can be ingeniously manipulated.
There are stark differences between traditional software development and LLMs. Traditional software is reliable, consistent, testable, and has well-defined protocols, which allows for clear ethical boundaries. In contrast, LLMs present a unique challenge due to their complex, emergent behavior and the sophisticated moderation required to govern them.
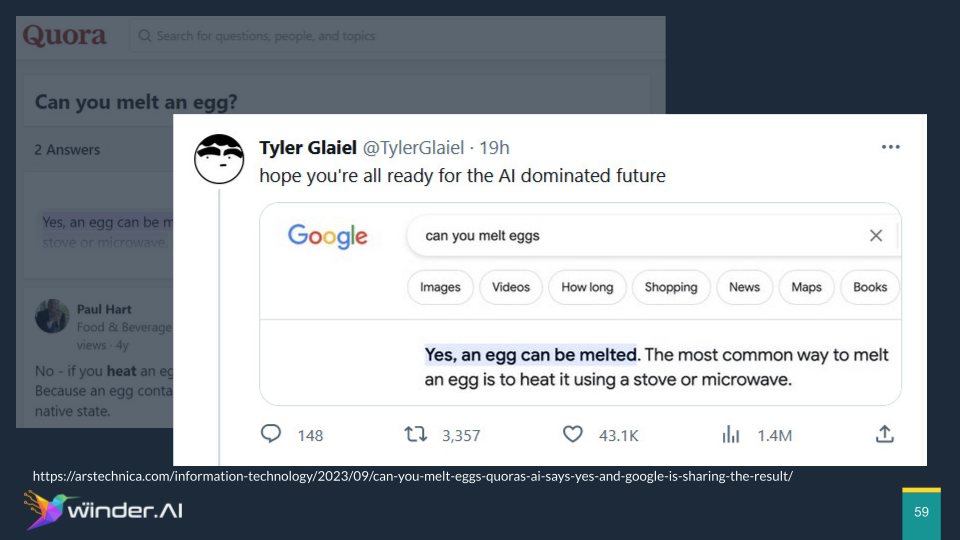
An intriguing point of discussion was the issue of feedback loops in LLMs. A real-world illustration of this problem was shared, drawing from a recent event that went viral on Twitter. The website Quora, known for its high SEO rankings, introduced a feature that utilized an LLM to provide answers to questions. An example highlighted was a question about melting an egg, to which the LLM erroneously responded affirmatively. This incorrect answer could then potentially circulate through search engines like Google, reinforcing the misinformation and causing the LLM to learn from its own mistaken output. This scenario underscores a significant and complicated feedback loop that does not occur in traditional software engineering or most machine learning applications, emphasizing the unique and convoluted challenges in deploying and hardening LLMs.
Section 7: Demo
In the final section I showcase the intricacies of fine-tuning a large language model (LLM), specifically demonstrating the process using the Falcon 7B model. The experience of setting up the environment with the correct libraries and dependencies was emphasized to be quite challenging, highlighting the rapid development and immature state of the supporting software.
The Falcon 7B model, while not revolutionary in architecture, gained significant performance improvements from being trained on a clean dataset. I’ve explained the importance of loading the correct tokenizer, as it’s a crucial part of the training process, and detailed the memory considerations when deploying the model on a GPU.
Furthermore, I walked through the code required for generating text using the model, using the transformers library’s generate function with specific settings to control the generation process, like the top-k and top-p sampling methods.
An interesting experiment was conducted where the model was fine-tuned on Beatles lyrics, requiring a significant amount of data cleaning to maintain the structural integrity of the songs. I stressed the adaptability of LLMs to learn domain-specific language and concepts, which can be applied to any proprietary data or internal company databases.
The training process was described as taking just over an hour with the specified settings before the loss stabilized, suggesting the model was successfully integrating the new data. Post-training, I archived the model and uploaded it to Google Drive, demonstrating persistence and retrieval of the trained model.
Finally, I introduce an application of a diffusion model by Stability AI called stable audio, which generates music from text inputs. I provided a live demonstration of generating music and reading out the generated song lyrics, which were curated from the freshly trained LLM. The presentation concluded with a reminder of the potential of LLMs to improve with more data and the performance of a generated song that humorously reflected on the topic of language models.
Final Thoughts
In a comprehensive exploration of large language models (LLMs), we traced the evolution of AI language understanding from its heuristic-based infancy to the sophisticated, predictive capabilities of today’s models, highlighting milestones like Word2Vec and the revolutionary Transformer architecture.
We delved into the complexities of building LLMs, including the intricate training processes that refine models using vast datasets and human feedback for accuracy, ethics, and safety. The critical role of data preparation was emphasized, noting that the careful selection and curation of training data are as crucial as the models themselves.
Moreover, we examined the trade-offs and innovations in model training, such as adapter models, and the concept of quantization to address the prohibitive memory demands of cutting-edge LLMs. Deployment challenges were mentioned, stressing the vulnerability of LLMs to adversarial attacks and the importance of hardening them against such threats, while also recognizing the unpredictability of feedback loops that can perpetuate misinformation.
A live demo using the Falcon 7B model served to practically illustrate the end-to-end process of fine-tuning an LLM, showing its remarkable adaptability to specific domains like music creation, proving that despite the potential pitfalls, the continuous refinement of these models opens up new frontiers for their application in various sectors.
Questions and Contact
If you have any questions, please feel free to reach out to me at phil@winder.ai. If you have any need for large language model development or consulting services, the please visit our dedicated services pages for more information.
Links and References
Important Milestones
- 1966: Eliza (Web Demo)
- 2013: Word2Vec – Embeddings
- 2014: Sequence to Sequence – RNNs, the idea of modelling sequences
- 2017: Transformers – Attention mechanism, no need for RNNs
- 2018: BERT – Bidirectional training
- 2018: Generative Pre-Training – GPT1
- 2019: Scale – GPT2
- 2020: Few Shot Learners – GPT3 – Context
- May 2022: “Think Step by Step” – Reasoning
- InstructGPT Paper
- Our book on Reinforcement Learning
Best Practices
- Massive data is better than your data…
- “data from online sources is sufficient to train models which show performance that is competitive with those trained on curated/editorial corpora. We stress that proper filtering and clean-up of crawled data is necessary” – https://arxiv.org/pdf/2201.05601.pdf
- “almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary” – https://arxiv.org/abs/2305.11206
- Massive data + your data is even better.
- “complimenting Common Crawl data with high-quality cross-domain curated data can boost zero-shot generalization” – https://arxiv.org/pdf/2210.15424.pdf
- Curation is hard
- “curation is labour intensive: typically, each source requires specialized processing, while yielding a limited amount of data. Furthermore, licensed sources raise legal challenges.” – https://arxiv.org/pdf/2306.01116.pdf
- No free lunch
- “Because different datasets can have different error distributions (even for the same error type), no single automatic cleaning algorithm is always the best.” https://arxiv.org/pdf/1904.09483.pdf
- Don’t use magic data cleaners
- “while two datasets may contain errors of the same type, the distributions of those errors can be vastly different. Therefore, practitioners should never make arbitrary cleaning decisions dealing with dirty data in ML classification tasks.” – https://arxiv.org/pdf/1904.09483.pdf
- Clean data is better than more data
- “stringent filtering and deduplication could result in a five trillion tokens web only dataset suitable to produce models competitive with the state-of-the-art” – https://arxiv.org/pdf/2306.01116.pdf
- “if cleaning a dataset has a particular impact for one ML model, cleaning is likely to have the same type of impact for other models as well.” https://arxiv.org/pdf/1904.09483.pdf
- Don’t rely on magic fixes (e.g. robust model techniques)
- “For many cases, data cleaning leads to a better end model compared with robust ML.” https://arxiv.org/pdf/1904.09483.pdf
- Human insight is still best
- “the results of human cleaning are better than the best automatic cleaning method” https://arxiv.org/pdf/1904.09483.pdf
- “including additional tokens in the LLM’s tokenizer before fine-tuning improves the measurement of the prediction model in most cases” – https://arxiv.org/pdf/2309.11295.pdf
Data Sources
Training and Modelling
- What Language Model to Train if You Have One Million GPU Hours? – https://arxiv.org/abs/2210.15424v1
- parameter-efficient fine-tuning (PEFT) – https://github.com/huggingface/peft
- Quantization – https://github.com/TimDettmers/bitsandbytes & https://github.com/PanQiWei/AutoGPTQ
- LLM “Programming” – https://mr-ranedeer.com/
Deployment and Hardening
- Adversarial attacks – https://llm-attacks.org/
- Attacking web application firewalls with reinforcement learning
- https://github.com/huggingface/text-generation-inference – parallelism, streaming, batching
- https://github.com/vllm-project/vllm – alternative, speeeeeed.
- https://developer.nvidia.com/triton-inference-server – AWS support, parallelism, robust
- https://www.langchain.com/ – The OG, great for workload orchestration