301: Data Engineering
- Published
- Author
Your job depends on your data
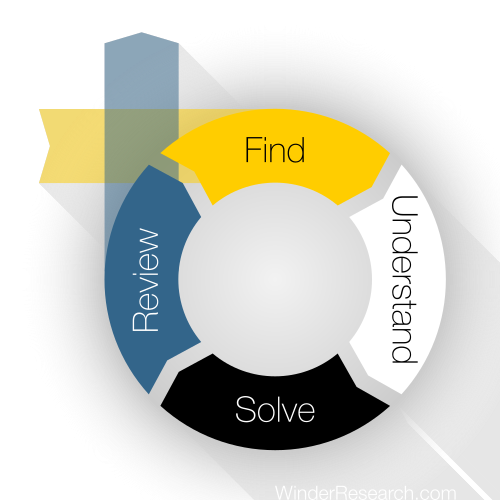
The goal of this section is to:
- Talk about what data is and the context provided by your domain
- Discover how to massage data to produce the best results
- Find out how and where we can discover new data
???
If you have inadequate data you will not be able to succeed in any data science task.
More generally, I want you to focus on your data. It is necessary to understand your data before building a model.
Read more