
COVID-19 Logistic Bayesian Model
Building upon the previous simple exponential model, in this post I look at using a logistic model for modeling COVID-19 cases.
 Dr. Phil Winder
/
8 min
Dr. Phil Winder
/
8 minBuilding upon the previous simple exponential model, in this post I look at using a logistic model for modeling COVID-19 cases.
Dr. Phil Winder
/
8 min
Building upon the previous simple exponential model, I implement backtesting to quantify prediction error.
Dr. Phil Winder
/
6 min
Learn how to use pymc3 for Bayesian modelling of COVID-19 cases.
Dr. Phil Winder
/
5 min
An introduction to the Athena project and using bayesian analysis for COVID-19 modeling.
Dr. Phil Winder
/
5 min
Little data? No problem! Best practices for starting an ML project with little or no data. Also how to handle sensitive data and recommendations on what models to use.
 Hajar Khizou
/
11 min
Hajar Khizou
/
11 min
This presentation will discuss in what circumstances bad data can affect your project along with some high-profile case studies. We will then spend as much time as we have going through some of the techniques you will need to fix that bad data. This is aimed toward those with intermediate-level Data Science experience.
Dr. Phil Winder
/
1 min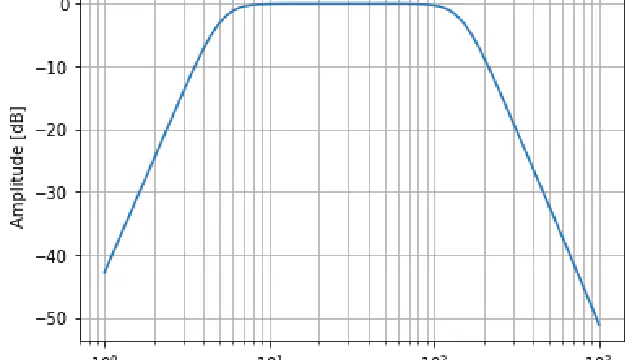
Learn about how to implement the fastest time-series filters in Python.
Dr. Phil Winder
/
7 minA comparison of Reinforcement Learning frameworks focusing on modularity, ease of use, flexibility and maturity by Phil Winder
Dr. Phil Winder
/
37 min
Announcement: I have agreed to write a new book for O'Reilly on Reinforcement Learning. Read more.
Dr. Phil Winder
/
4 min
Google has announced a new range of AI products to help Engineers rapidly develop and deploy models. Winder.AI helped develop content for the AI-Hub.
Dr. Phil Winder
/
3 minCase studies and industry analysis from our team. No hype, roughly monthly.